


Интернет помнит всё, даже то, что из него уже удалили. Всё хранится в огромном Веб-архиве — специальном сервисе по адресу web.archive.org. Сегодня рассказываем о том, кто это придумал, зачем нужен Веб-архив и как им пользоваться.
Кто и зачем придумал Веб-архив
Веб-архив, или Wayback Machine, придумала некоммерческая организация «Архив Интернета» с главным офисом в Сан-Франциско. Она сохраняет веб-страницы, оцифрованные аудио- и видеозаписи, книги и программное обеспечение. Официально Веб-архив запустили в 2001 году, но данные хранятся с 1996 года.
Веб-архив сохраняет веб-страницы в интернете в разные периоды. Когда Веб-архив заходит на какой-то сайт, он делает его «снимок» и сохраняет в хранилище.
Веб-архив можно воспринимать как музей интернета или как машину времени. В нём можно посмотреть, какие версии веб-сайтов есть в хранилище, увидеть по ним, что менялось, и найти данные, которые были изменены или уже недоступны.
Что именно хранится в Веб-архиве
Периодически роботы Веб-архива приходят на разные сайты и копируют всё, что там есть:
- HTML-страницы, CSS-стили и скрипты, которые относятся к сайту;
- картинки, видео и музыку;
- разные файлы и документы, которые в этот момент доступны на сайте.
В итоге сервис сохраняет на свои серверы полную копию всего, что нашёл на странице. Когда Веб-архив приходит на сайт в следующий раз, он не удаляет предыдущую копию, а сохраняет новую. Благодаря этому мы можем посмотреть, как выглядел этот же сайт какое-то время назад — месяц, год или 10 лет до этого. Для этого просто заходим на Веб-архив, вводим адрес сайта и выбираем, за какую дату хотим посмотреть копию сайта.
Но не факт, что нужный сайт будет в архиве, — робот до него мог и не добраться за всё это время. А если добрался, то не факт, что у него будет копия именно нужной даты. Короче, Веб-архив — это музей, в котором много экспонатов, но не все экспонаты там есть :-)
 Защита важных файлов: автоматический бэкап за пять минут
Защита важных файлов: автоматический бэкап за пять минут Что такое бэкап и зачем он нужен
Что такое бэкап и зачем он нужен Настраиваем сервер для своего облачного хранилища
Настраиваем сервер для своего облачного хранилища Вместо Dropbox: ваше собственное облачное хранилище файлов
Вместо Dropbox: ваше собственное облачное хранилище файлов Автоматизация на скриптах: делаем умный бэкап
Автоматизация на скриптах: делаем умный бэкап Вместо офиса: как отказаться от решений Google и Microsoft на случай сами знаете чего
Вместо офиса: как отказаться от решений Google и Microsoft на случай сами знаете чего Устанавливаем суверенный облачный офис
Устанавливаем суверенный облачный офис Превращаем домашний компьютер в полноценный веб-сервер: пошаговое руководство
Превращаем домашний компьютер в полноценный веб-сервер: пошаговое руководствоКак сохраняется
Процесс сохранения сайтов происходит так же, как это делают Яндекс или Google. У всех этих систем есть поисковые роботы, которые сканируют веб-страницы. Таких роботов иногда называют краулерами или пауками, а сканирование страниц — парсингом. Роботы Яндекса или Google сохраняют текстовое содержимое и ссылки, а роботы Веб-архива сохраняют контент.
Архив интернета не уточняет, по какому алгоритму работают его роботы, но известно, что они собирают только общедоступные данные. Содержимое сайта можно скрыть для сохранения в Веб-архиве через пароль или параметры индексирования.
С чего начать: главная страница и календарь
Чтобы посмотреть, что Веб-архив может рассказать об интересующем нас сайте, заходим на web.archive.org и вводим в строке поиска адрес этого сайта:
Веб-архив покажет всю информацию, которая у него есть по этому сайту, и разделит данные по таким вкладкам:
- Календарь.
- Коллекции.
- Изменения.
- Общее, или Summary.
- Карта сайта.
- Адреса — URLs.
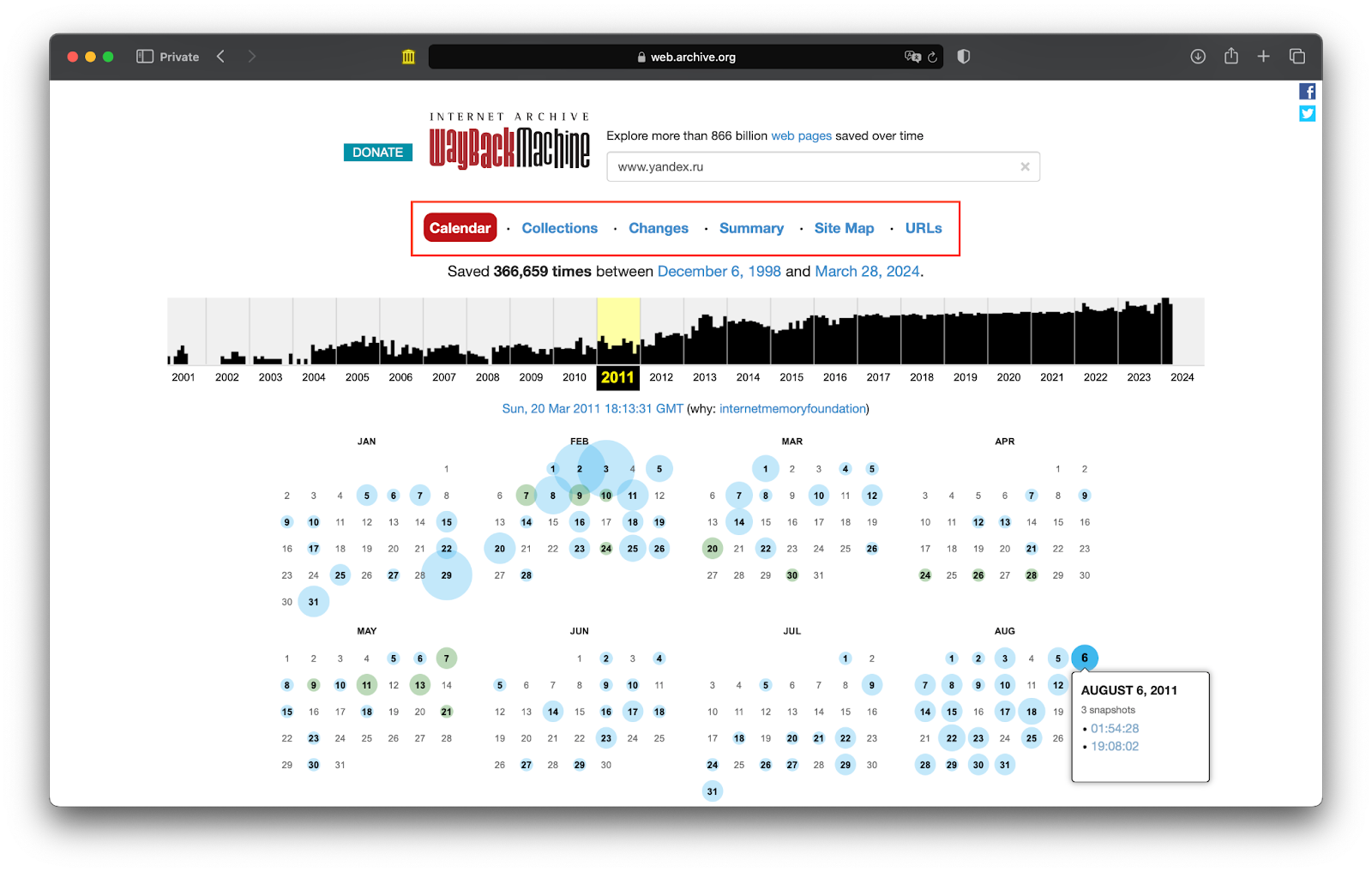
Чаще всего пользуются календарём — он показывает, сколько сохранений было сделано за каждый год в разные дни, когда робот заходил на сайт. При этом дни могут быть отмечены разными цветами — синим, зелёным или красным в зависимости от результата посещения:
- Синий — Веб-архив зашёл на сайт и успешно сделал сохранение. Это те версии, которые можно смотреть.
- Зелёный — сайт перенаправил Веб-архив на другой адрес.
- Красный — сайт не загрузился из-за ошибки.
За каждый день записано время, во сколько и что именно произошло. Если Веб-архив приходил на сайт несколько раз за день — записывается каждое посещение.
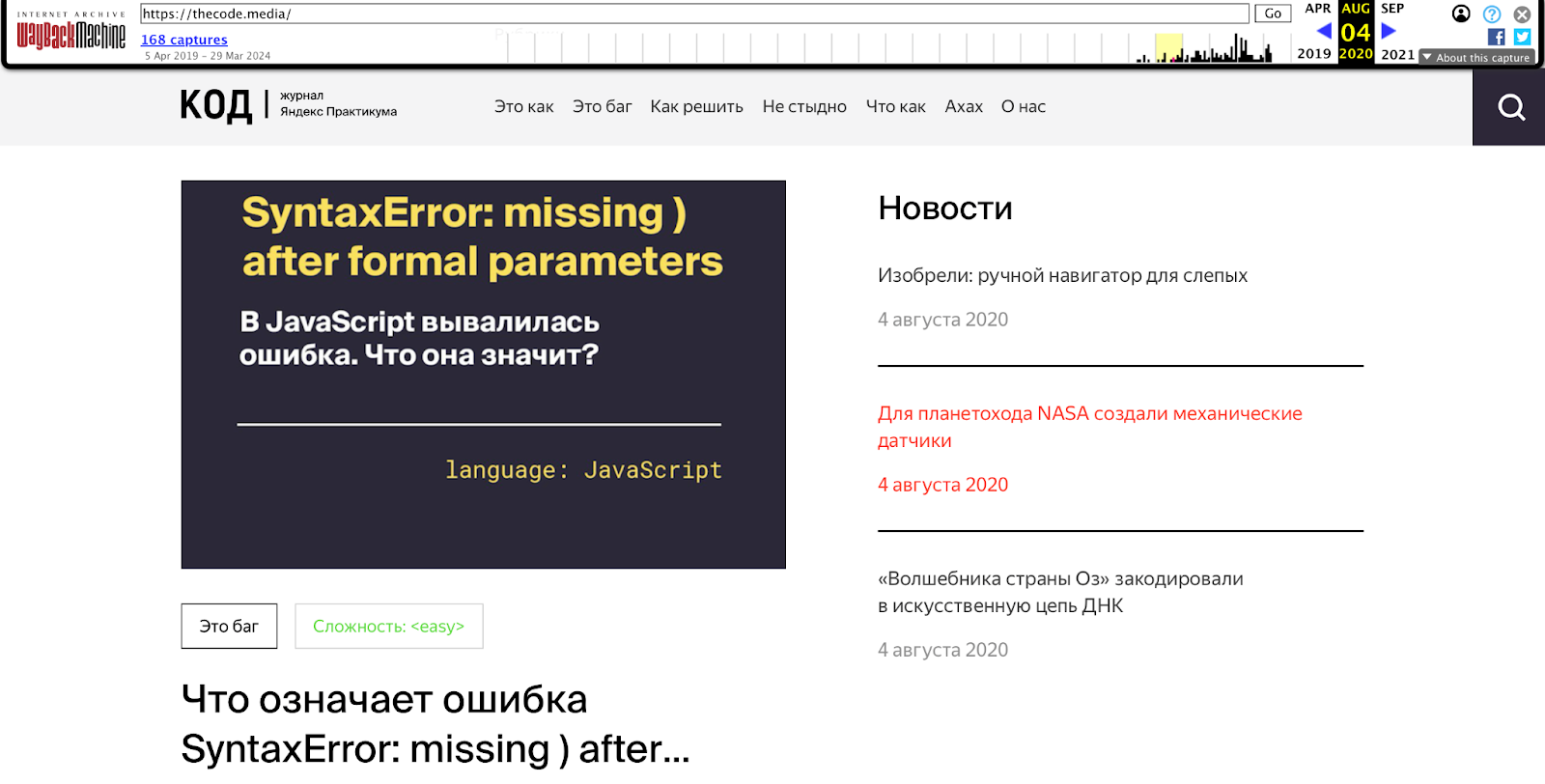
Если открыть одну из сохранённых версий, отмеченных синим, мы увидим страницу в том виде, как она выглядела в то время:
Но может быть так, что мы нажимаем на синюю дату, а нас отправляют на совсем другой сайт. Это потому, что Веб-архив запомнил, что он точно приходил на эту веб-страницу, но на ней стояла переадресация, а поисковый робот этого не понял. Получается, что посещение формально было, но копии сайта у сервиса за этот день нет. Такое бывает.

Различия между версиями страниц
Можно сравнить две версии одной страницы, сохранённые в разное время. Для этого открываем вкладку Changes, выбираем две разные даты и нажимаем Compare:
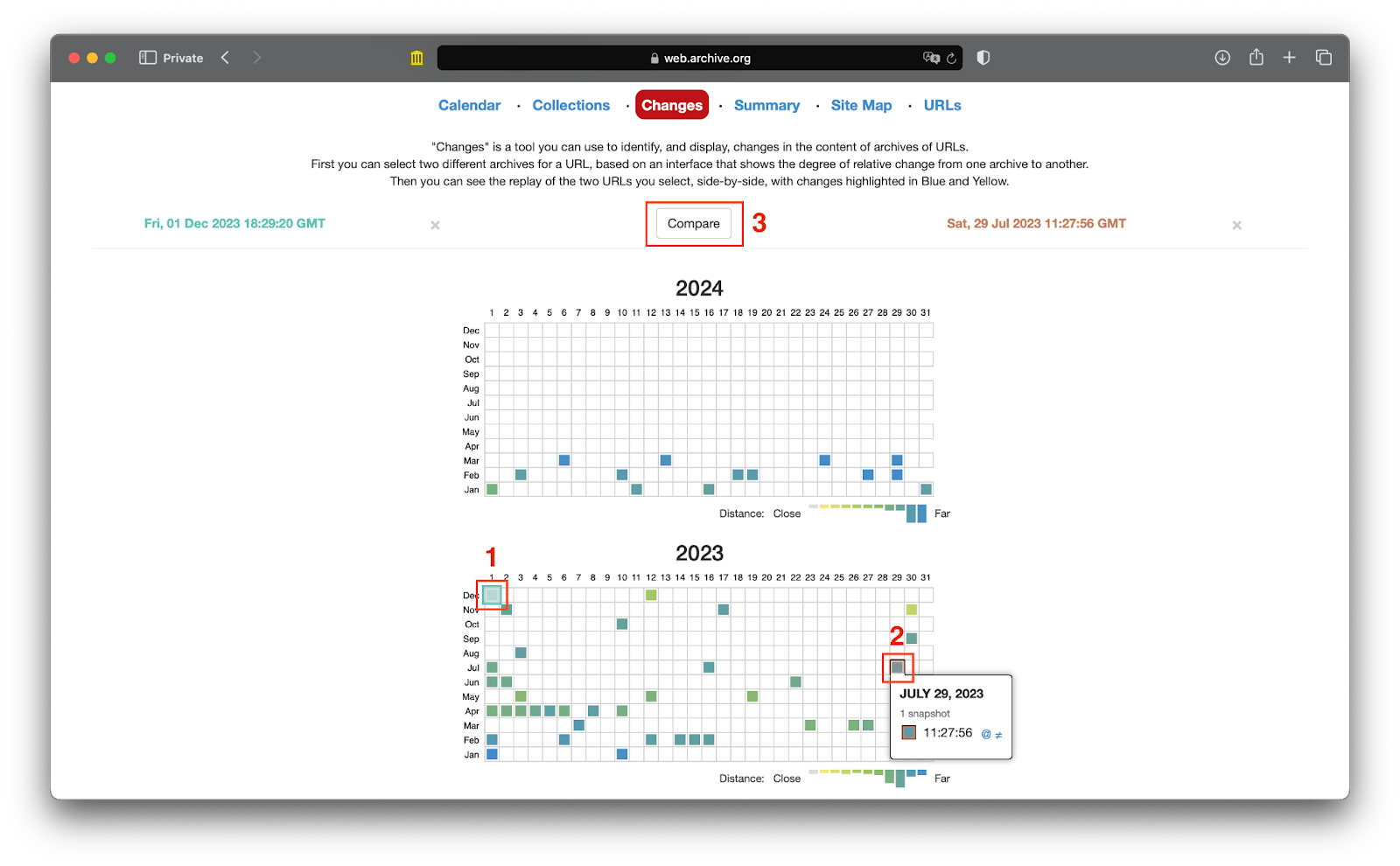
Две версии сайта откроются рядом друг с другом, чтобы было удобнее сравнивать:
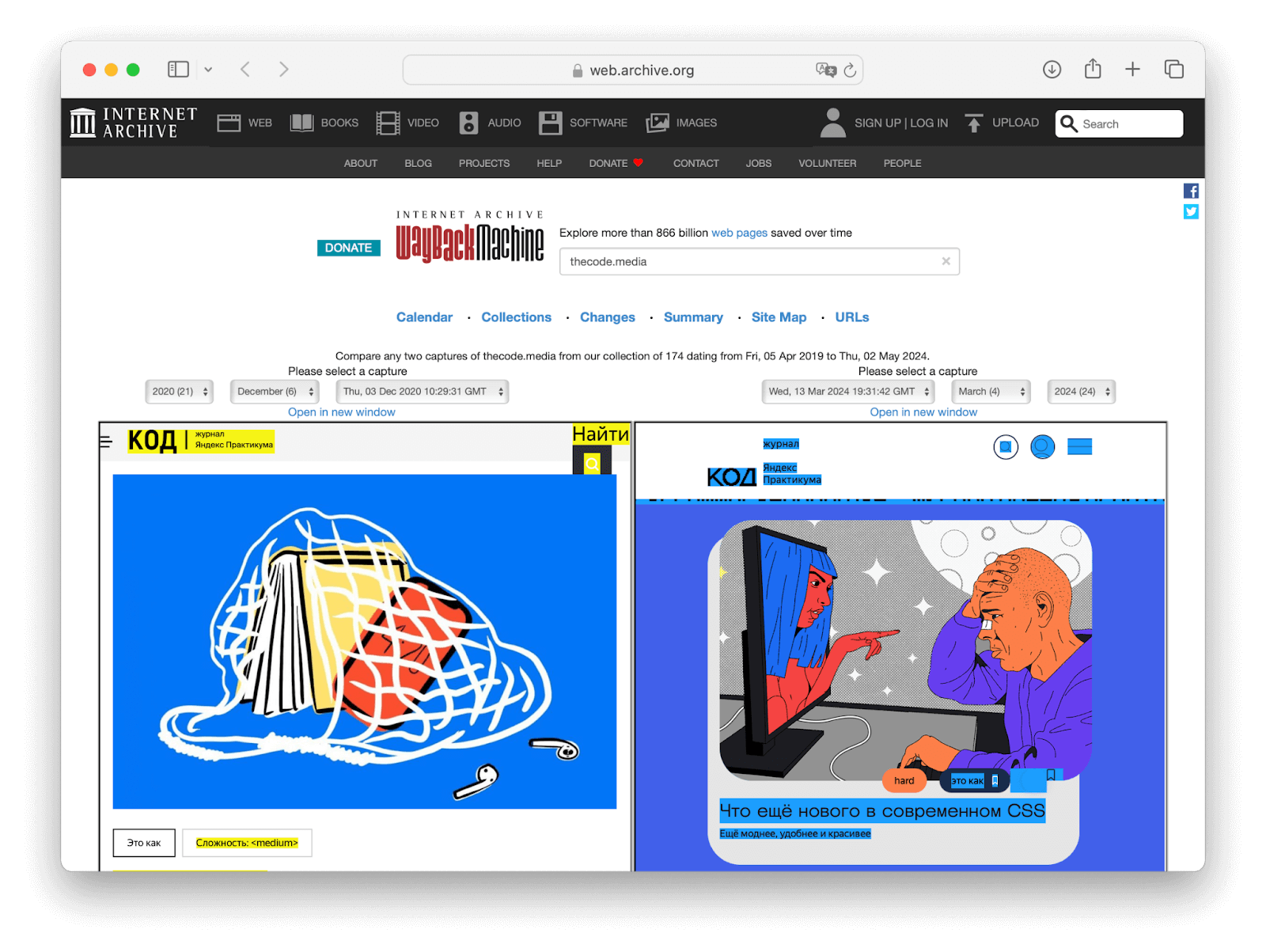
Общая сводка по изменениям
Если мы перейдём на вкладку Summary, Веб-архив выдаст нам в общем виде то, что он знает про этот сайт. Для наглядности всё упаковано в графики и таблички.
Вверху можно выбрать:
- период в годах, за какое время нужна аналитика;
- какие медиатипы содержимого сайта нам интересны.
Медиатипы (MIME-types) — это специальные метки, которые состоят из двух частей: тип файла и его формат. Например, image/jpeg означает, что это изображение формата jpeg.
Например, можно увидеть, что с 2019 по 2023 год Веб-архив сохранил с сайта «Кода» 19 тысяч jpeg-картинок, 15 тысяч png-картинок и 14 тысяч страниц:
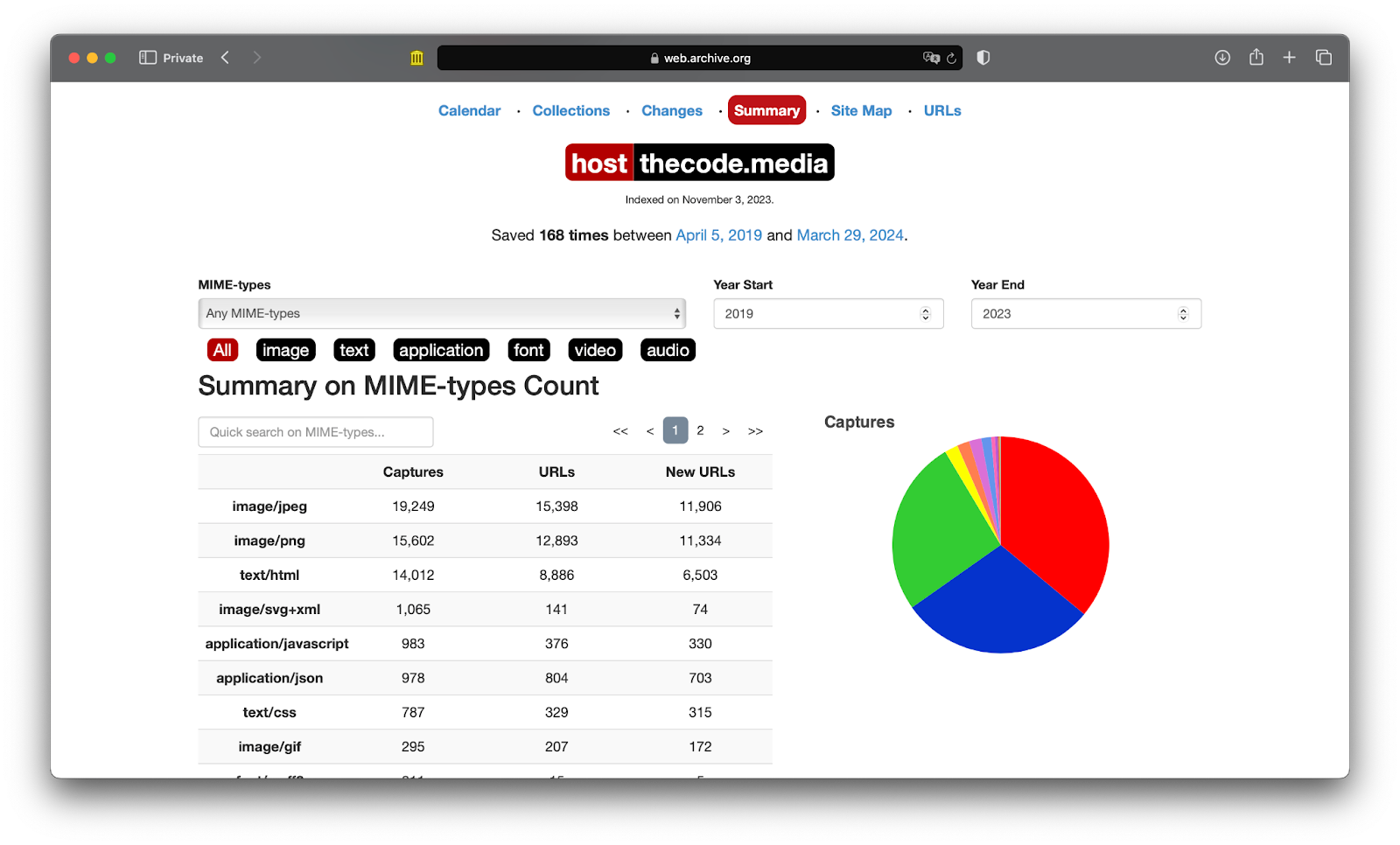
График сохранений за год
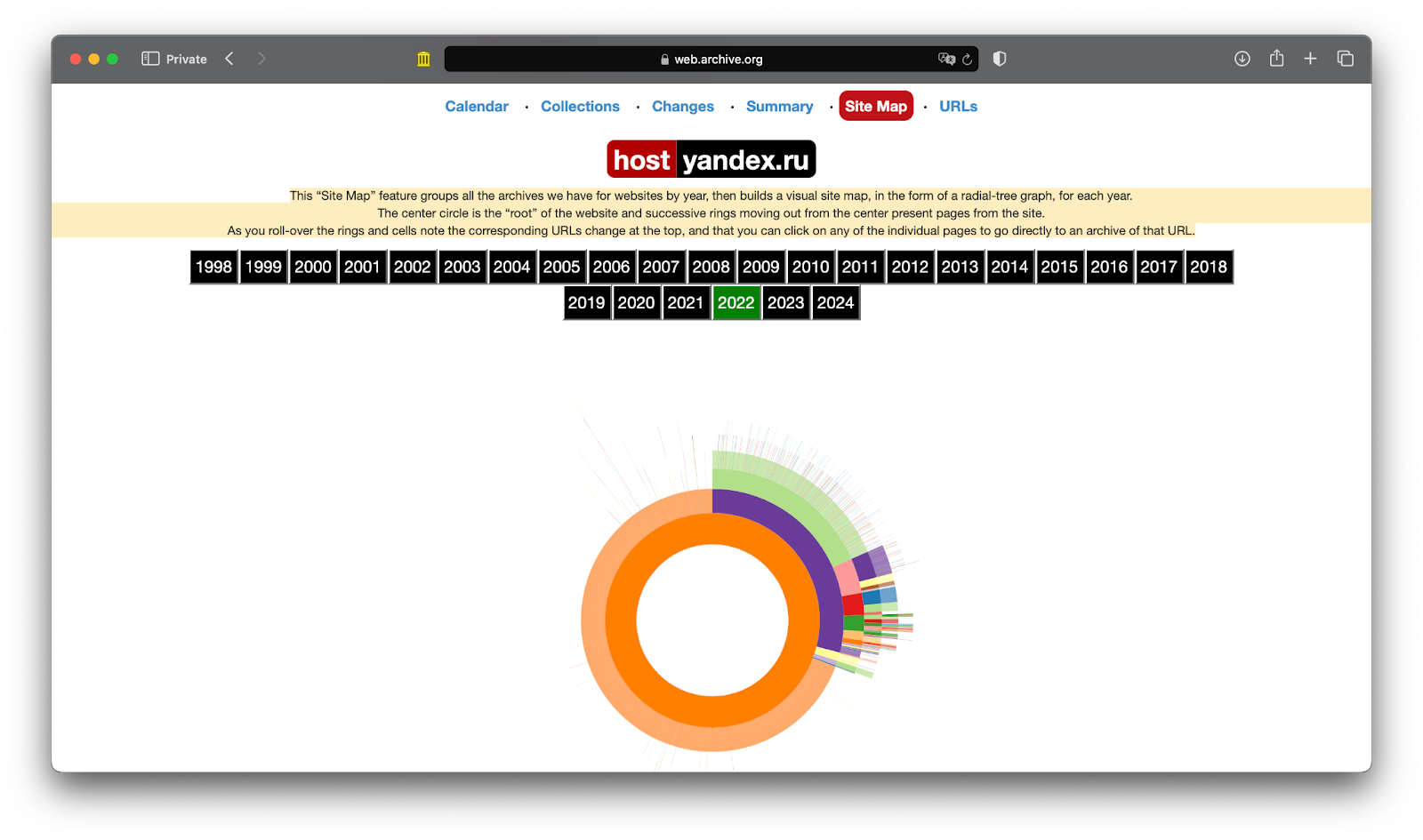
Чтобы посмотреть, как часто и что именно сохранял Веб-архив с сайта, выбираем вкладку Site Map и видим на ней круговую диаграмму, которая показывает уровни вложенности страниц, что нашёл поисковый робот сервиса.
В центре расположен главный URL страницы: thecode.media. На следующем круге лежат страницы первого уровня вложенности, например thecode.media/best-seller. И так далее, в зависимости от того, сколько внутренних страниц на сайте и какой там уровень вложенности.
Если на графике мало информации, это значит, что Веб-архив сохранил мало копий сайта за этот год. Возможно, в это время сайт запретил посещения для поисковых роботов или по какой-то причине начала работать переадресация на другой адрес.
Смотрим таблицу по датам сохранений
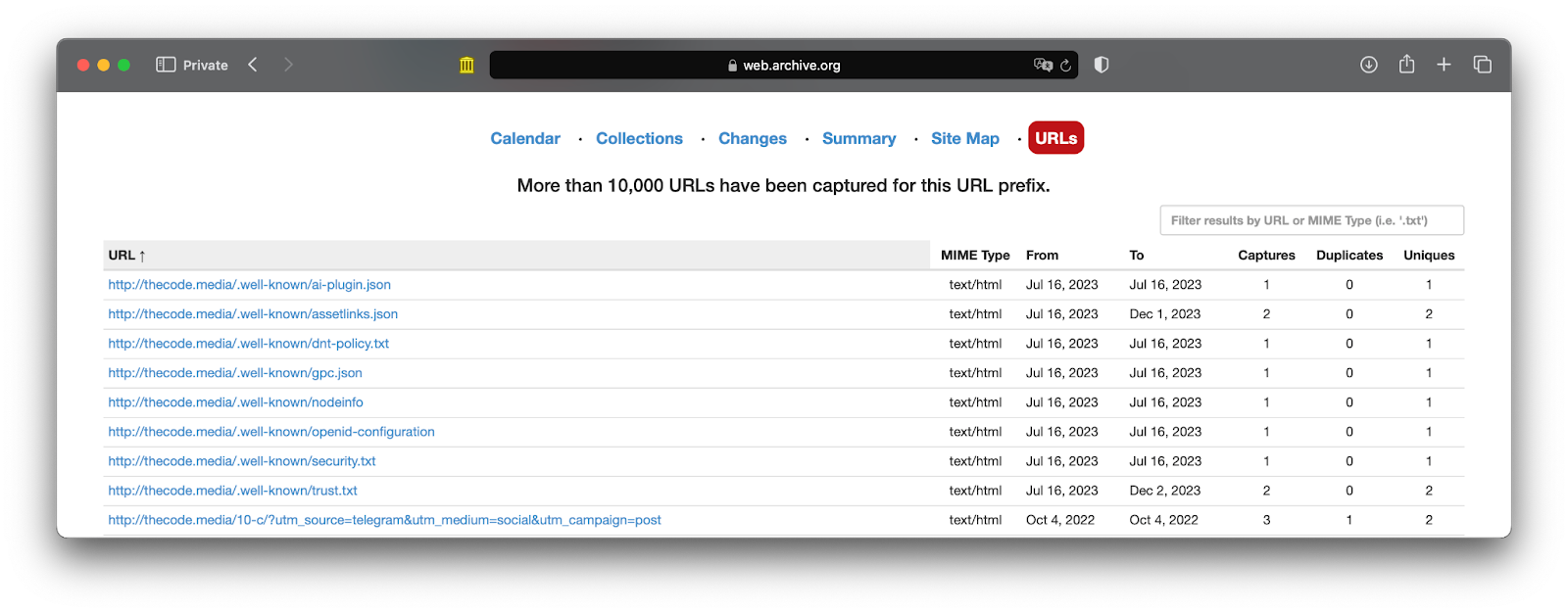
На последней вкладке URLs можно посмотреть таблицу с информацией для каждой страницы сайта:
- URL страницы.
- Медиатип сохранённых данных.
- Дата, когда Веб-архив первый раз зашёл на эту страницу и начал периодически её сохранять.
- Дата последнего сохранения.
- Общее количество сохранений.
- Количество раз, когда сервис заходил, а страница не менялась, а рядом — сколько раз всё же менялась.
В окне фильтра над таблицей можно посмотреть данные определённого раздела, чтобы увидеть только веб-страницы в нужной части сайта. Это можно сделать и в главном окне поиска, если написать адрес внутренней страницы на сайте и добавить к нему символ *. Например, запрос yandex.ru/maps/* покажет только страницы, адреса которых начинаются с yandex.ru/maps/.

И что мне со всем этим делать?
Веб-архив — это большая запасная копия значительной части интернета. С его помощью можно сделать много полезного:
- Получить доступ к уже не работающим сайтам.
- Найти комментарии, которые удалили.
- Посмотреть историю изменений на сайте.
- Подтвердить право на свои публикации, если вы автор.
- Использовать данные для исследований, если вы маркетолог или аналитик.
- Найти доказательства для суда. Например, в Веб-архиве есть отдельная коллекция «Архив Трампа».
Как добавить свою страницу в архив или убрать из него
Любой пользователь, даже неавторизованный на Веб-архиве, может отправить поисковых роботов Веб-архива сделать снимок страницы. Для этого нужно зайти в подраздел web.archive.org/save/, ввести адрес сайта и нажать Save page. А ещё для этого есть расширения для браузеров и своё мобильное приложение.
Попросить убрать из архива копии сайта может только его владелец. Для этого нужно написать письмо на info@archive.org, указать адрес сайта и представить доказательства того, что вы им владеете.
Где всё это хранится
Вот последние данные об инфраструктуре «Архива интернета» за 2021 год. Сейчас данных уже больше, но порядок цифр всё равно впечатляет:
- 750 серверов;
- 1300 виртуальных машин:
- 30 000 устройств хранения данных:
- более 20 000 жёстких дисков:
- общий объём накопителей почти 200 петабайт.
Чтобы хранить такой огромный массив данных, у организации есть свои здания, серверные и персонал. Для надёжности всё хранится минимум в двух экземплярах. Кроме Сан-Франциско, копии есть в Нидерландах и Египте.
Если вы думали, что у вас много дисков с бэкапами и они уже занимают много места на полке, посмотрите сюда — у ребят настолько много данных, что диски хранят уже в контейнерах. Интересно, что такой способ хранения обходится дешевле, чем держать эти же данные в облаке:

Что ещё есть в «Архиве интернета»
На серверах и физических складах сегодня хранится:
- 835 миллиардов веб-страниц;
- 44 миллиона книг и текстов;
- 15 миллионов аудиозаписей;
- 10,6 миллиона видеороликов;
- 4,8 миллиона изображений;
- 1 миллион программ.
Для каждой оцифрованной книги у «Архива» есть физическая копия. Принцип такой: «Архив Интернета» покупает книгу, оцифровывает её, а затем любой желающий может взять электронную версию книги на 2 недели.
Из-за того, что организация делает общедоступным контент, на котором другие компании зарабатывают, иногда на «Архив Интернета» подают в суд. Например, в 2020 году «Архив» судился сразу с несколькими издательствами, когда нарушил правило выдавать одному читателю одну книгу за раз.
Получается, что «Архив» не выставляет в общий доступ коммерчески защищённые продукты. Но и не забывает о тех, которыми уже можно делиться. Вот что опубликовали в Твиттере организации 1 января 2024 года, когда у Disney истекли права на первую версию чёрно-белого Микки-Мауса:
Частые вопросы о веб-архиве
Насколько полным и точным является снимок страницы в веб-архиве? Всегда ли он показывает сайт точно так, как его видел пользователь?
Снимок — это не копия сайта, а скорее его «фотография» с элементами кода. Wayback Machine сохраняет HTML, CSS и картинки, которые были доступны в момент визита робота.
Чего не будет:
- Сложного интерактива: формы, поиск по сайту, корзина и личный кабинет работать не будут — серверная часть (PHP/Python/Node.js) в архив не попадает.
- Внешних файлов: если картинка или шрифт подгружались с другого сервера, который умер или запретил доступ роботу, вместо них будет пустота.
- Скрытого контента: всё, что требовало логина или пароля, для робота невидимо.
Как веб-архив справляется с современными динамическими сайтами на React, Vue.js и с бесконечной прокруткой?
С переменным успехом. Старые роботы веб-архива видели только «пустой» HTML, поэтому многие SPA-сайты (одностраничные приложения) в архиве выглядят как белый экран. Современные механизмы, особенно при ручном сохранении через кнопку Save Page Now, научились выполнять JavaScript и сохранять отрисованный контент.
Но есть нюанс: контент, который подгружается только при скролле (бесконечная лента) или при клике на кнопки, скорее всего, не сохранится. Вы увидите только «первый экран» сайта.
Можно ли с помощью веб-архива найти удалённые изображения, видео или PDF-документы, если известен их старый URL?
Да, это один из самых полезных кейсов. Если у вас есть прямая ссылка на файл (например, site.com/report.pdf), вставьте её в поиск. Если робот хоть раз натыкался на этот файл, он его отдал.
Лайфхак: если вы не помните точную ссылку, можно использовать «звёздочку» для поиска всех файлов определённого типа. Введите в поиск site.com/*.pdf, и архив покажет список всех сохранённых PDF-документов с этого домена.
Учтите: если файл был защищён паролем или доступен только авторизованным пользователям, архив его не сохранил. И если роботы просто не заходили на эту ссылку, файла тоже не будет.
Есть ли API у Wayback Machine и как с его помощью автоматизировать поиск или сохранение данных?
Да, и их даже несколько:
- Availability API: cамый простой способ проверить, есть ли у архива снимок конкретного URL. Возвращает JSON с датой последнего снимка.
- CDX Server API: мощный инструмент для сложного поиска, например «найти все картинки с сайта X за 2015 год».
- Save Page Now API: позволяет автоматически отправлять страницы на архивацию.
Официальная документация находится здесь: archive.org/developers.








