


Когда мы говорили о разметке в Маркдауне, то там смысл был такой: есть текст, а мы его размечаем специальными символами, чтобы он хорошо выглядел. Теперь перейдём на этап выше — будем форматировать данные на уровне логики с помощью XML.
👉 XML нужен для работы с техническим текстом, где всё строго, упорядоченно и логично. Его, конечно, можно применить и к художественному тексту, но выйдет так себе.
Что такое XML-формат
XML — это сокращение от eXtensible Markup Language, а переводится это как «расширяемый язык разметки». Смысл XML в том, чтобы выстроить внутри документа логическую структуру — чтобы было видно, что к чему относится и как всё связано между собой, в каком формате представлены данные.
Зачем нужен
С помощью XML можно:
- записать оргструктуру компании или любую другую иерархию — «этот подчиняется тому»;
- разметить текст по смыслу — «тут важное, там второстепенное, вот это поясняет вон то»;
- хранить типовые данные — например, имена артистов, названия их альбомов и треки, или настройку какой-нибудь программы, или скрипты;
- разметить веб-страницу по смыслу и отдать эту разметку алгоритму, который сам нарисует дизайн;
- разметить текст для дальнейшего машинного обучения;
- хранить результаты работы программ, которые работают с текстом, — например, ничто не мешает текстовым редакторам хранить документы со всем оформлением в формате XML.
И многое другое, где нужен порядок, структура и работа с текстовыми данными.
В чём сила XML
Сила XML в том, что данные здесь представляются как обычный текст, размеченный тегами (как в HTML). Например, чтобы записать оргструктуру компании в XML, не нужно рисовать схему в графическом редакторе, достаточно правильно разметить текст с именами и должностями. Файлики получаются маленькими, их легко обрабатывать.
И ещё сила XML в том, что эти данные может прочитать и обработать компьютер. Например, если мы передаём ему оргструктуру компании, компьютер поймёт её: кто кому подчиняется, что куда входит и т. д. Для сравнения: если скормить компьютеру схему, нарисованную в графическом редакторе, он её не поймёт.
А вот если XML хорошо составлен, его также может понять человек.

Из чего состоит XML
Внешне XML очень похож на HTML: в нём тоже всё пишется в угловых скобках, есть закрывающие теги и параметры — аналоги классов и стилей. Но, в отличие от HTML, здесь нет обязательных тегов или вообще каких-то обязательных элементов. Объясним, как это работает, на примере.
Допустим, у нас есть такой текст, из которого нужно сделать XML-документ:
«По состоянию на 22 мая 2025 журнал „Код“ работает и в редакции есть главред Михаил Полянин и авторы Кристина Тульцева и Игорь Росляков».
Теги и атрибуты
Основное тело XML-документа состоит из тегов и атрибутов.
Теги образуют всю структуру файла. Если вы немного знакомы с HTML, то увидите, что здесь они выглядят так же. В основном теги бывают открывающие (<tag>) и закрывающие (</tag>). Но, в отличие от HTML, в XML можно использовать любые теги, которые нужны по логике создания файла.
Атрибуты — это дополнительные параметры тега, которые записываются внутри открывающего тега. Они заключены в кавычки. Может выглядеть так:
<tag attr="value">
Комментарии и специальные символы
Комментарии в XML такие же, как в HTML. Это текстовые пометки, которые не влияют на остальной файл:
<!-- это комментарий, он не влияет на файл -->
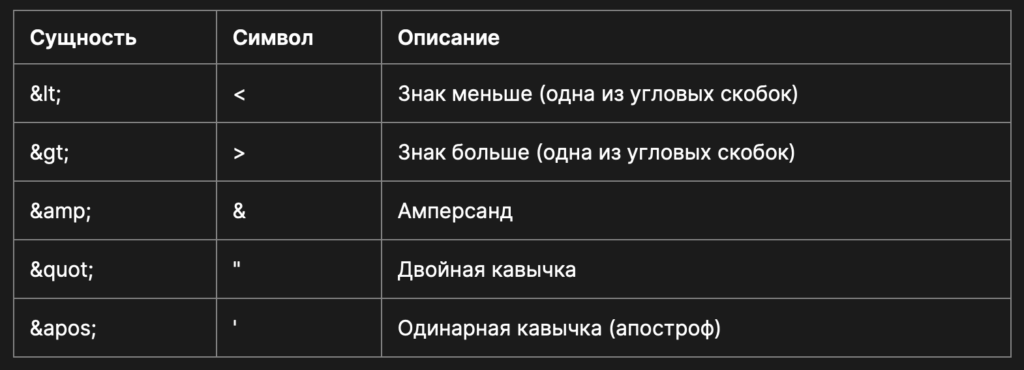
Спецсимволы — это символы вроде угловых обозначений тегов. Мы не можем их использовать между настоящими тегами в чистом виде, потому что тогда файл сломается: он подумает, что мы открываем новый тег или делаем ещё какое-то действие, а нам на самом деле нужно просто поставить символ в текст.
Для работы со спецсимволами нужно использовать соответствующие им наборы других символов, которые ещё называются сущности. Если мы поставим в текст сущности, машина на выходе выведет как раз тот спецсимвол, который нам нужен.
Например, амперсанд & относится к числу спецсимволов, поэтому нельзя сделать так:
<title> Sanford&Son</title>
Вместо этого нужно так:
<title> Sanford&Son</title>
Длиннее, зато работает.
Вот основные спецсимволы и соответствующие им сущности:
Пролог
Любой XML начинается с пролога, это первая строка документа. В ней нужно написать, что перед нами именно XML:
<?xml version="1.0" encoding="UTF-8"?>
Пролог говорит, что ниже будет XML-разметка. Иначе программа-обработчик не будет знать, что с ним делать — рисовать как HTML или выводить как просто текст?
Что есть в прологе:
- Версия XML. Обычно 1.0.
- Кодировка для корректной работы с символами текста. В нашем примере это UTF-8.
Корневой элемент
Внутри XML-документа всегда есть корневой тег-элемент — внутри него лежит всё остальное. Так как в XML мы придумываем названия для разметки сами, то пусть этот элемент будет называться actual (это название может быть любым):
<?xml version="1.0" encoding="UTF-8"?>
<actual>
<!-- содержимое корневого элемента -->
</actual>
Содержимое внутри корневого элемента
Теперь разбираем содержимое. Первое, что мы видим в документе, — это дата, поэтому можем сделать отдельный раздел со статусом издания. В него будет входить значение Active (издание работает) и два параметра — дата последней проверки и статус этой проверки. Сам элемент мы назовём status:
<?xml version="1.0" encoding="UTF-8"?>
<actual>
<!-- содержимое корневого элемента -->
<status lastUpd = "22.05.2025" checked = "true">
Active
</status>
</actual>
Это очень похоже на стили и классы в HTML, но работает иначе: мы просто указываем параметры и их значения, а не подключаем какие-то внешние данные или правила.
Ещё вы могли заметить, что мы пишем дату в нестандартном формате (с точки зрения компьютера). Так можно: если мы потом будем писать обработчик этого XML, мы сможем научить его читать именно этот формат даты.
👉 Это история о том, что XML — это просто полочки, на которые мы раскладываем данные. Какие там данные — ему не важно.
Добавим ниже сведения про название журнала:
<?xml version="1.0" encoding="UTF-8"?>
<actual>
<!-- содержимое корневого элемента -->
<status lastUpd = "22.05.2025" checked = "true">
Active
</status>
<media type = "online">
Журнал «Код»
</media>
</actual>
Новый элемент мы назвали media — так человеку будет проще прочитать и понять, что внутри, а компьютеру всё равно. Последнее — добавим информацию о составе редакции. Обратите внимание, что появилась вложенная структура: внутри элемента person есть три дочерних элемента: name, lastname и role. Это значит, что они относятся к родительскому элементу, а не живут сами по себе:
<?xml version="1.0" encoding="UTF-8"?>
<actual>
<!-- содержимое корневого элемента -->
<status lastUpd = "22.05.2025" checked = "true">
Active
</status>
<media type = "online">
Журнал «Код»
</media>
<!-- редакция -->
<person>
<name>
Михаил
</name>
<lastname>
Полянин
</lastname>
<role>
главред
</role>
</person>
<person>
<name>
Кристина
</name>
<lastname>
Тульцева
</lastname>
<role>
редактор
</role>
</person>
<person>
<name>
Игорь
</name>
<lastname>
Росляков
</lastname>
<role>
редактор
</role>
</person>
</actual>
Таким способом можно разобрать на логические составляющие любой технический или информационный документ — от инструкции к чайнику до ежегодного отчёта для инвесторов. Главное, не запутаться в элементах и чётко понимать, что от чего зависит и куда вкладывается.

Секции CDATA
Это блок с дополнительными тегами внутри тега. Внутри можно вставить любой текст, даже спецсимволы. Выглядит так:
<cdata_example>
<![CDATA[
Внутри CDATA можно писать <, >, & без экранирования
]]>
</cdata_example>
CDATA — способ сказать машине, чтобы она не обрабатывала этот блок как XML. Получается что-то вроде больших комментариев, но не совсем. CDATA затрудняет работу: поиск по этому разделу становится сложнее, он может мешать созданным шаблонам.
Главное, что XML создан для работы со структурированными данными, а CDATA работает как бы против этой идеи: это чёрный ящик, внутри которого может быть что угодно. Его нельзя проверить схемой, и он не поддерживает механизмы для усиления надёжности работы XML.
Иногда CDATA бывает полезен, но это особые случаи. Например, нужно встроить в файл фрагмент текста с большим количеством спецсимволов, такой как код.
Где нужен XML-формат
XML применяют везде, где нужно выделить логическое содержимое документа, чтобы потом его можно было как-то обработать. Например, если у вас есть размеченный XML-файл с названием и характеристиками товаров, то можно научить сервер обрабатывать его как угодно: выводить название в заголовке или простым текстом, понимать, где лежит цена, откуда брать описание и к какому разделу отнести этот товар.
Ещё XML применяют в API, когда идёт ответ от сервера в виде XML-файлов.
Как открыть XML-файл
Способов несколько. Всё зависит от того, что вы потом хотите сделать с файлом.
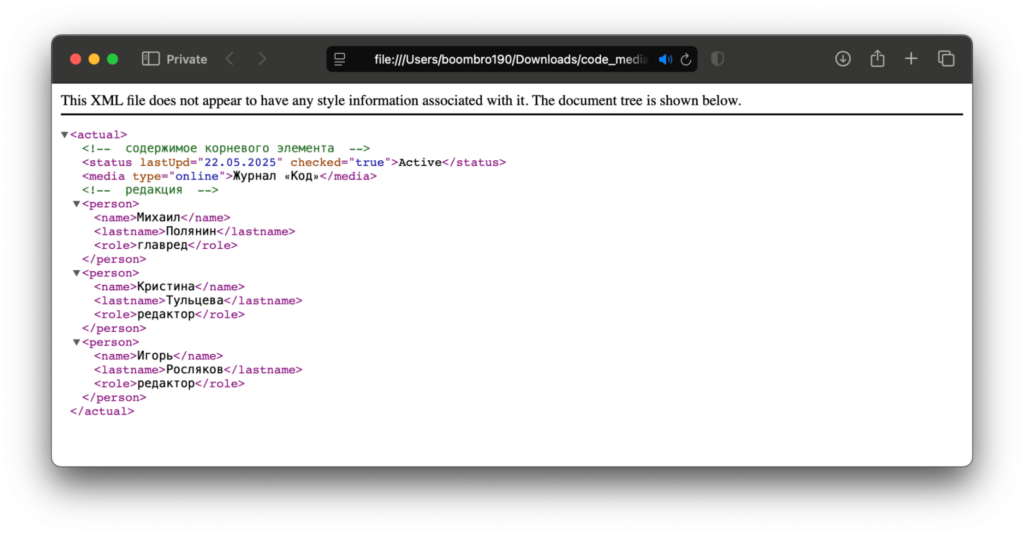
На компьютере
Если файл нужно только открыть и просмотреть, проще всего перетащить его в поле адресной строки браузера. Редактировать нельзя, зато вся структура сразу видна:
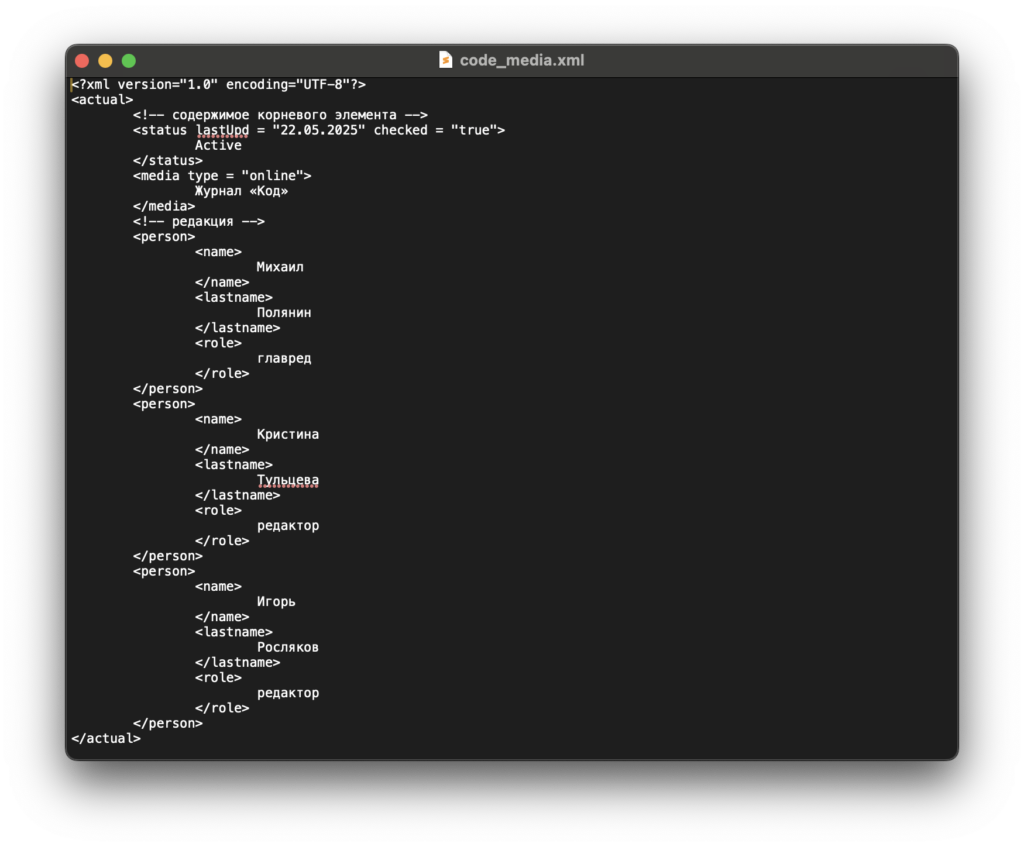
Самый простой инструмент для редактирования — Блокнот на Windows и TextEdit на MacOS. Можно менять содержимое, но просматривать его не так удобно, потому что нет подсветки синтаксиса:
Более продвинутый вариант — использовать текстовые редакторы кода. Так будет выглядеть открытый файл в редакторе Sublime Text:
Самый мощный вариант — поставить IDE и всё делать в ней. Например, бесплатный настраиваемый Visual Studio Code:
На мобильных устройствах
По умолчанию XML на смартфоне можно открыть в браузере, так же как на компьютере:
Если скачать отдельное приложение (их много, можно выбрать), файл можно открывать и редактировать в нём:
Создание и редактирование XML файлов
Понадобится любой текстовый редактор или редактор кода. Минус текстового редактора в том, что там нет подсветки, поэтому лучше поставить что-нибудь для программирования.
Если не хотите разбираться в средах разработки, поставьте Sublime Text — он простой и удобный, там можно работать с любым текстом, его достаточно для всех простых задач, а если прокачать дополнительными плагинами, то можно спокойно писать и запускать код.
Для простого XML-файла нужно запомнить несколько правил.
Сначала пишем пролог:
<?xml version="1.0" encoding="UTF-8"?>
Потом ставим корневой тег:
<?xml version="1.0" encoding="UTF-8"?>
<root>
<!-- тут будет всё содержимое XML -->
</root>
Внутри корневого тега можно создавать любые другие, но нужно помнить:
- Не забывайте ставить парные теги — один открывающий, другой закрывающий. Если работаете в IDE, для этого можно установить дополнительный плагин, который будет делать это за вас.
- Регистр важен: нельзя написать один тег заглавными буквами, а другой строчными.
- Все атрибуты внутри тегов должны быть указаны в кавычках:
<book id="101">. - Спецсимволы, такие как угловые кавычки или амперсанд, нужно экранировать.
Созданный XML можно проверить валидаторами. Например, jsonformatter.org:
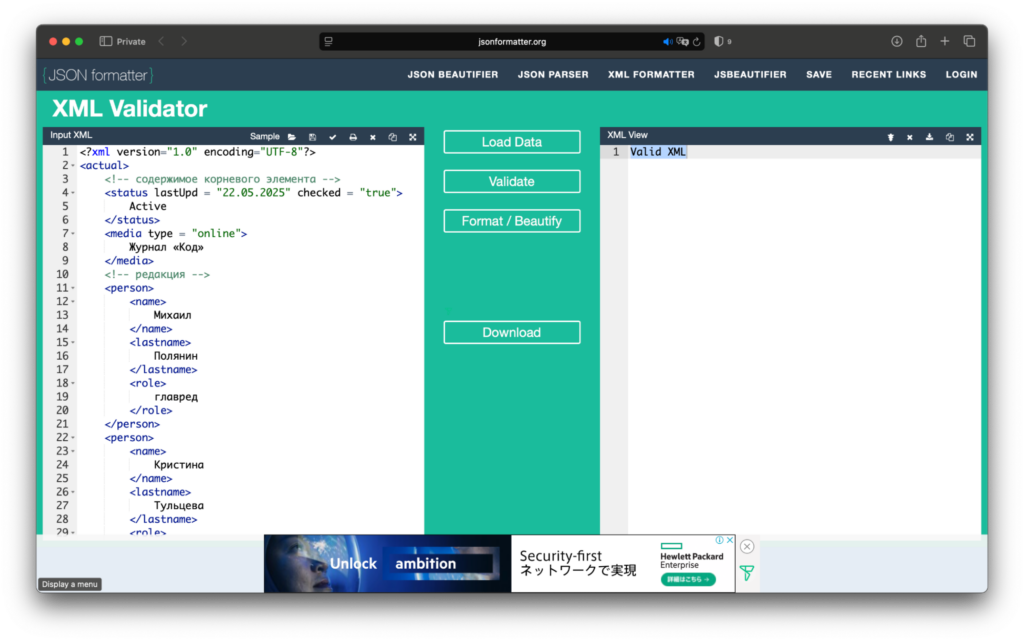
Или w3schools.com:
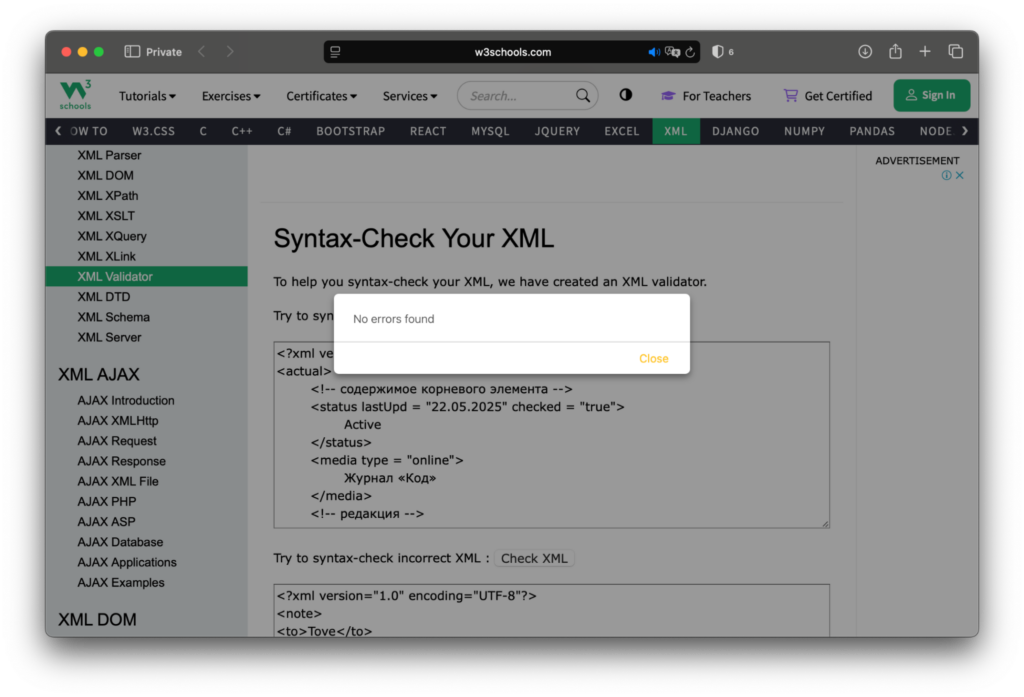
Что дальше
В другой статье придумаем свой XML-формат и научим сервер с ним работать. Так тоже можно. В конце концов, это ИТ, тут можно вообще почти всё.











