


В прошлый раз мы написали конвертер на Python, который берёт текст из файла с расширением .txt и сохраняет в файл Word c расширением .docx. Сегодня сделаем кое-что посложнее: напишем конвертер для файлов разметки Markdown.
Если вы ни разу не программировали на Python, почитайте нашу статью:
Что делаем
Наш предыдущий конвертер брал текстовый файл, считывал содержимое и сохранял в документ Word. В этот раз сделаем такое:
- Напишем сам конвертер. Он будет смотреть в указанный файл с расширением .md и аккуратно переводить его содержимое в .docx. При этом сохранится оформление Markdown-разметки.
- Добавим обработку исключений. Если пользователь конвертера попросит взять несуществующий файл или с другим расширением, скрипт объяснит, что так делать нельзя.
- Всё это мы вынесем в отдельный файл, который можно будет импортировать одной строчкой кода в любую другую программу.
Для конвертации текста в Word мы использовали библиотеку python-docx. Сейчас она не подойдёт, потому что не понимает разметку Markdown.
В этот раз мы используем Pandoc — универсальный конвертер файлов, с которым можно работать из командной строки. Чтобы он был доступен в скрипте, мы подключим специальную библиотеку pypandoc. Такие библиотеки называют обёртками — в них как бы заворачивают другую программу, чтобы она была доступна для работы через код.
В чём особенность Markdown
Markdown — это язык простой текстовой разметки. В отличие от файлов .txt, в файлах .md можно делать заголовки разного уровня, выделять текст курсивным или жирным начертанием, вставлять блоки кода и картинки. В маркдауне оформляются статьи с аккуратным лаконичным дизайном и документация на GitHub и других ресурсах, поэтому для технических писателей это стопроцентный мастхев.
Если мы просто прочтём файл маркдауна и скопируем в Ворд, оформление потеряется. Чтобы сохранить его, мы подключим специальную библиотеку, которая понимает разметку и аккуратно переносит её в другие файлы.
Пишем файл разметки
Для Markdown-файла мы используем несколько возможностей:
- Вставим картинку — для этого положим её в ту же папку, что и файл .md.
- Добавим заголовки нескольких уровней.
- Напишем предложение, в котором будут жирный текст, курсив и ссылка.
- Добавим список с чекбоксами.
Так код будет выглядеть в файле input.md:

# Заголовок первого уровня
## Заголовок второго уровня
### Заголовок третьего уровня
Этот текст содержит **жирный текст**, _курсив_ и [ссылку](https://thecode.media/txt-to-doc-script/).
Чек-лист:
- [x] Выполненный пункт
- [ ] Невыполненный пункт
- [ ] Невыполненный пунктА так код будет отображаться в программе, которая понимает разметку Markdown:

 Как сделать игру на Python бесплатно
Как сделать игру на Python бесплатно Делаем тетрис на Python
Делаем тетрис на Python Создаём на Python скрипт, который делает из простого текстового файла .txt вордовский файл .docx
Создаём на Python скрипт, который делает из простого текстового файла .txt вордовский файл .docx Пишем на Python тесты для проверки знаний
Пишем на Python тесты для проверки знаний Прокачиваем учебные тесты на Python: добавляем чтение из документа
Прокачиваем учебные тесты на Python: добавляем чтение из документа Добавляем графический интерфейс программе для учебных тестов
Добавляем графический интерфейс программе для учебных тестов Работа с файлами в Python: полное руководство по open(), readline() и записи данных
Работа с файлами в Python: полное руководство по open(), readline() и записи данныхУстанавливаем библиотеки
Для работы нам понадобятся два инструмента: библиотека pypandoc и сам Pandoc. Библиотека будет отправлять наш файл на сервер Pandoc и принимать готовый документ с расширением .docx.
Для этого нужно выполнить две команды:
pip install pandoc
pip install pypandoc
Это можно сделать как в командной строке…
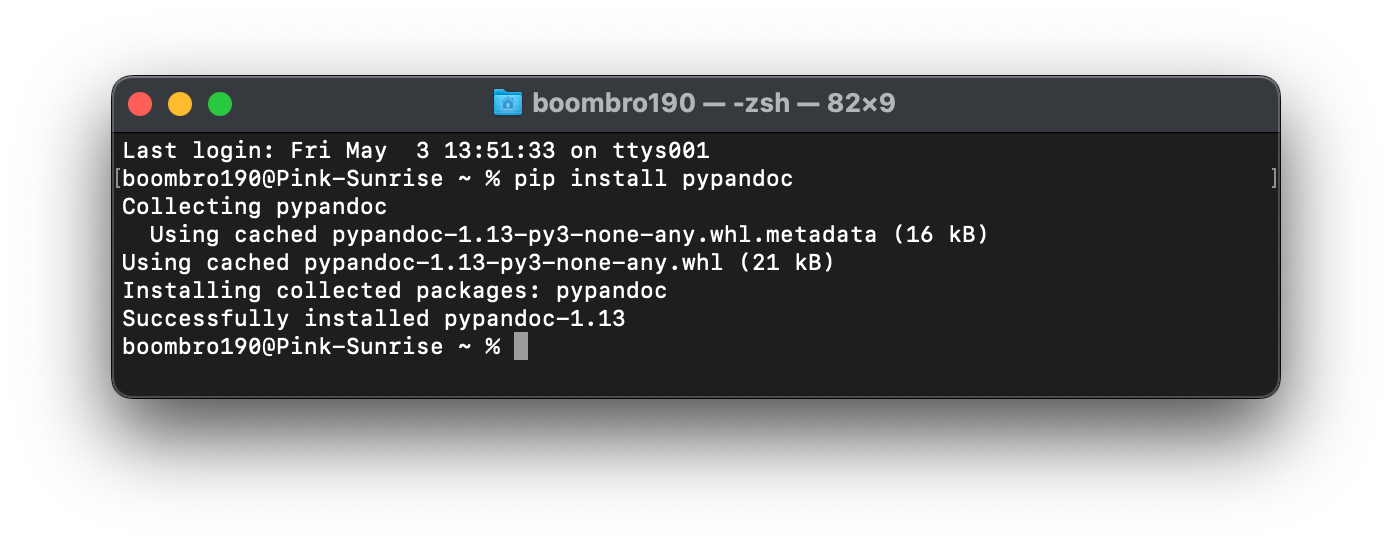
…так и в терминале, если вы работаете в IDE, например PyCharm или Visual Studio Code:
Пишем функцию-конвертер
Импортируем в наш скрипт модуль convert_file из библиотеки pypandoc для конвертации файлов:
from pypandoc import convert_file
После этого весь процесс будет происходить в одной строке:
convert_file(‘input.md’, ‘docx’, outputfile=’output.docx’)
Файл input.md должен лежать в той же папке, что и наш скрипт. Для итогового вордовского файла можно брать любое название.
Теперь оформим красиво. Положим код в функцию, чтобы давать ей файлы для конвертации в отдельных переменных, а после выведем сообщение о проделанной работе:
# объявляем функцию
def markdown_to_docx(md_file, docx_file):
# запускаем процесс конвертации
convert_file(md_file, 'docx', outputfile=docx_file)
# пишем, что всё прошло хорошо
print("Конвертация успешно завершена.")Теперь можно вызвать эту функцию в любом месте и задать путь до нужных файлов. У нас они лежат рядом со скриптом, поэтому пишем только их название:
markdown_to_docx(‘input.md’, ‘output.docx’)
Теперь сделаем так, чтобы программа могла сама справляться с некоторыми ошибками при запуске.
Добавляем проверку файла
В разработке нужно предусматривать обработку ввода — например, если пользователь вводит кириллические буквы вместо латинских или номер телефона, в котором меньше 10 цифр. Мы добавим две проверки: убедимся, что у файла правильный формат и что он вообще есть.
Чтобы итоговый скрипт мог проверять существование файла, нужен встроенный в Python модуль для работы с операционной системой os. Устанавливать его не надо, достаточно просто подключить:
import os
Для проверки формата нужно поработать со строками, потому что путь и название файла мы задаём строкой:
markdown_file = ‘input.md’
Теперь используем готовые методы для работы со строками:
- метод
.lower()приведёт все символы в названии файла к нижнему регистру, если пользователь вводит название заглавными буквами; - метод
.endswith()проверит расширение файла.
Если какая-то из проверок нашла ошибку, останавливаем код. Самый простой способ прервать выполнение функции — использовать команду return.
# объявляем новую функцию
def markdown_to_docx(md_file, docx_file):
# проверяем расширение файла: такая конструкция вернёт True или False
if not md_file.lower().endswith('.md'):
# останавливаем выполнение функции, если получили True
return
# проверяем, существует ли файл Markdown: такая конструкция вернёт True или False
if not os.path.exists(md_file):
# останавливаем выполнение функции, если получили True
returnЭтого достаточно для обработки ошибок, но мы сделаем ещё лучше: добавим обработку исключений.
Вызываем исключения через операторы Try и Except
В Python можно объявить, что мы пробуем выполнить какой-то код, а если что-то пойдёт не так — сказать коду, что делать дальше. Для этого используют конструкцию try-except.
После слова try мы выполняем код, который теоретически может вызвать ошибку, а в блоке except объясняем компьютеру, какие могут быть ошибки и что делать в этом случае.
У нас будет три варианта исключений:
- у файла неправильное расширение — это тип исключения ValueError;
- файл не найден — это FileNotFoundError;
- все остальные ошибки, которые относятся к общему типу Exception.
Для наших исключений мы подготовим сообщения и будем выводить для каждого своё:
# объявляем новую функцию
def markdown_to_docx(md_file, docx_file):
# пробуем обработать файл
try:
# проверяем расширение файла: такая конструкция вернёт True или False
if not md_file.lower().endswith('.md'):
# вызываем исключение, если на предыдущей строке получили True
raise ValueError("Указанный файл не является файлом Markdown.")
# проверяем, существует ли файл Markdown: такая конструкция вернёт True или False
if not os.path.exists(md_file):
# вызываем исключение, если на предыдущей строке получили True
raise FileNotFoundError("Указанный файл не найден.")
# конвертируем файл Markdown в файл Word (docx)
convert_file(md_file, 'docx', outputfile=docx_file)
# выводим на экран отчёт, что всё прошло хорошо
print("Конвертация успешно завершена.")
# объявляем исключения для проверки файлов и передаём сообщения, которые прописали в блоках if
except (ValueError, FileNotFoundError) as e:
print(f"Ошибка: {e}")
# если конвертация почему-то не удалась,
# объявляем исключение для всех остальных случаев и выводим на экран стандартный текст ошибки
except Exception as e:
print(f"Ошибка при конвертации: {e}")Теперь остановимся подробнее на том, как именно происходит работа с ошибками.
Обработка исключений
Если сработала проверка в блоке if, мы не прерываем программу командой return, а обрабатываем нужный тип исключения. Само исключение вызывается командой raise, после которой в скобках нужно написать понятное для пользователя сообщение об ошибке.
Главная обработка исключений происходит в блоках except. В каждом из них мы пишем тип исключения и соответствующее поведение: у нас это просто текст, который мы выводим на экран. Выглядит это так:
print(f”Ошибка: {e}”)
Строчная буква f перед кавычками означает, что внутри кавычек может быть переменная в фигурных скобках.
Конструкция as e сохраняет в переменную e сообщение из блока raise. Поэтому теперь, если произошло исключение ValueError, мы получим такое сообщение:
Ошибка: Указанный файл не является файлом Markdown.
Кладём скрипт в отдельный класс
Наш конвертер уже работает хорошо, но мы сделаем ещё лучше: сделаем так, чтобы можно было подключать его в другие скрипты командой import. Для этого используем классы, поэтому сразу создадим новый класс:
class Mark2doc:
Класс работает с помощью методов. В коде они выглядят точно так же, как функции, кроме того, что в скобках на первом месте обязательно должно стоять слово self. Чтобы превратить нашу функцию-конвертер в метод класса, нужно добавить к аргументам слово self.
Было:
def markdown_to_docx(md_file, docx_file):
Стало:
def markdown_to_docx(self, md_file, docx_file):
Теперь создаём новый объект на основе нашего класса, чтобы можно было использовать его как конвертер:
converter = Mark2doc()
Наконец, запускаем обработку с помощью этого объекта и переменных с именами файлов:
# записываем в переменную путь и название файла с разметкой Markdown
markdown_file = "input.md"
# записываем путь и названия для выходного документа Word
word_file = "output.docx"
# запускаем метод класса
converter.markdown_to_docx(markdown_file, word_file)Осталось сделать так, чтобы всё это можно было импортировать в другой скрипт. Для этого:
- Переименовываем файл Python-скрипта во что-то запоминающееся: у нас он называется markdown2docx.
- Создаём новый Python-скрипт.
- Первой строкой в новом файле пишем:
from markdown2docx import Mark2doc.
Теперь можно создавать объект конвертера и конвертировать файлы. Вот как это выглядит целиком:
# импортируем конвертер из другого скрипта
from markdown2docx import Mark2doc
# создаём объект класса
converter = Mark2doc()
# записываем в переменную путь и название файла с разметкой Markdown
markdown_file = "input.md"
# записываем путь и названия для выходного документа Word
word_file = "output.docx"
# запускаем импортированный метод класса
converter.markdown_to_docx(markdown_file, word_file)
Что дальше
Наш конвертер не совершенен, потому что у всех библиотек для автоматической конвертации есть свои проблемы: в одной не сохраняется форматирование списков, в других — картинки, третьи просто зависают.
Можно сделать идеальный конвертер, который будет сохранять всю возможную разметку Markdown. Для этого нужно:
- подключить 4 сторонние библиотеки и 2 модуля;
- добавить отдельный JSON-файл и записать в него стили, которые хотим видеть в Word;
- перевести Markdown в HTML;
- построчно парсить этот файл;
- для каждого встреченного тега задать верное поведение при переносе в Word.
Наш скрипт тоже можно улучшить — например, вызывать его без необходимости создания объекта класса. Займёмся этим в следующий раз.
# импортируем стороннюю библиотеку для конвертации
from pypandoc import convert_file
# импортируем встроенный модуль для работы с операционной системой
import os
# объявляем новый класс
class Mark2doc:
# пишем метод класса
def markdown_to_docx(self, md_file, docx_file):
# пробуем обработать файл
try:
# проверяем расширение файла: такая конструкция вернёт True или False
if not md_file.lower().endswith('.md'):
# вызываем исключение, если на предыдущей строке получили True
raise ValueError("Указанный файл не является файлом Markdown.")
# проверяем, существует ли файл Markdown: такая конструкция вернёт True или False
if not os.path.exists(md_file):
# вызываем исключение, если на предыдущей строке получили True
raise FileNotFoundError("Указанный файл не найден.")
# конвертируем файл Markdown в файл Word (docx)
convert_file(md_file, 'docx', outputfile=docx_file)
# выводим на экран отчёт, что всё прошло хорошо
print("Конвертация успешно завершена.")
# объявляем исключения для проверки файлов и передаём сообщения, которые прописали в блоках if
except (ValueError, FileNotFoundError) as e:
print(f"Ошибка: {e}")
# если конвертация почему-то не удалась,
# объявляем исключение для всех остальных случаев и выводим на экран системный текст ошибки
except Exception as e:
print(f"Ошибка при конвертации: {e}")










