


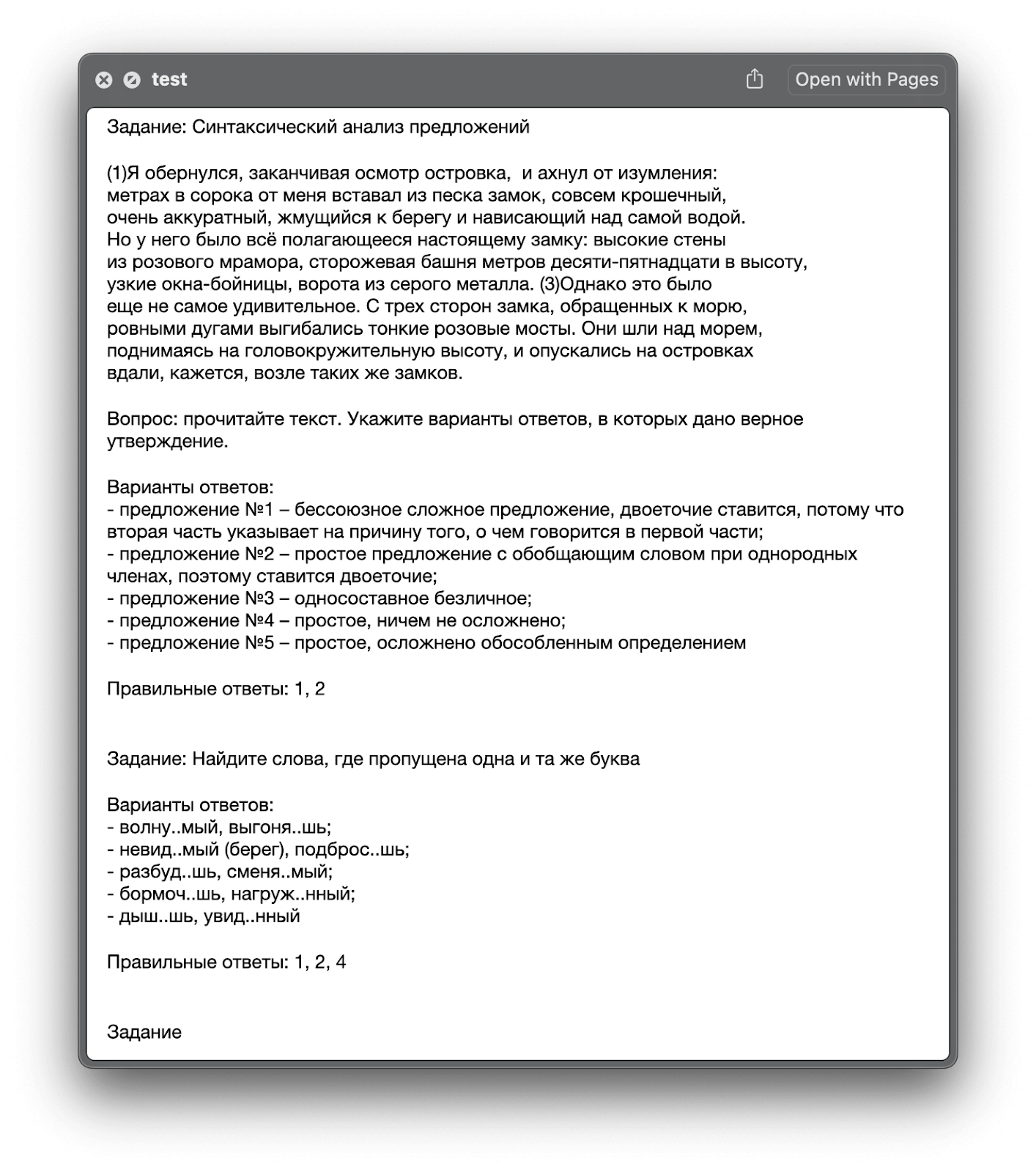
В прошлый раз мы написали на Python программу, которая выводила на экран тесты для проверки знаний и считала количество вопросов и правильных ответов. Сегодня доработаем наш проект: сделаем так, чтобы вопросы и ответы к ним хранились в документе Word, а наш код их читал и выдавал в случайном порядке.
Если вы только интересуетесь Python и начинаете его изучать, посмотрите наш мастрид, в котором мы собрали всё самое важное и интересное для старта в этом языке программирования.
Для работы нам понадобится Python. Если у вас его ещё нет, почитайте наши статьи:
Что сделали в прошлый раз
Предыдущая программа работала так:
- Мы брали готовые тесты и переносили их в код. Тексты заданий, вопросы, ответы — каждый раздел мы вставляли на своё место вручную.
- Программа всё это читала и выводила в консоли, каждый раз в одном порядке.
- Ответы можно было ввести через запятую, программа сравнивала их с правильными ответами и выдавала результат.
В общем, всё, что у нас было, — это код с заранее созданной строгой структурой тестов.
Что делаем сейчас и что понадобится
На этот раз мы создадим программу, которая будет брать тесты из файла Word и выводить их в случайном порядке. Для этого нам понадобится вордовский документ и несколько дополнительных модулей и встроенных конструкций Python:
- библиотека python-docx;
- регулярные выражения;
- встроенные модули
re,randomиtime; - коллекции данных — списки, множества и кортежи;
- генераторы списков;
- циклы;
- функции
split,join,mapиenumerate.
Библиотека python-docx нужна для работы с вордовскими файлами, потому что Python не умеет с ними работать по умолчанию.
Регулярные выражения и модуль re понадобятся при чтении документа. Чтобы программа понимала, где задание, а где варианты ответов, мы напишем специальные условия.
Модули random и time сделают тесты немного интереснее и естественнее: все задания будут выводиться в случайном порядке, а после ответа пользователя будет небольшая задержка, чтобы можно было успеть прочесть результат.
Списки — самая универсальная и часто используемая коллекция данных в Python. Они обозначаются квадратными скобками и могут хранить внутри любые элементы, которым присвоен свой номер, или индекс. Элементы списка можно изменять.
# пример списка
list_of_books = ['Улисс', 'Автостопом по галактике', 'Сто лет одиночества']Генератор списков позволит быстро создавать списки по указанной формуле с использованием цикла. Например, можно взять слово «генератор», извлечь из него каждую букву по отдельности и сделать из них новый список.
Множество — изменяемая неупорядоченная коллекция данных. Элементы множества всегда уникальны и не имеют номеров — эти два свойства нам пригодятся. В одном множестве будут храниться правильные ответы, а в другом — ответы пользователя. Даже если пользователь случайно дважды укажет одно и то же число, соответствующее варианту ответа, множество этого не заметит. Главное, чтобы в двух коллекциях были одни и те же элементы:
# эти два множества равны
set1 = {'Лев', 'Колдунья', 42}
set2 = {'Лев', 'Колдунья', 42, 'Колдунья', 'Лев'}Кортеж — неизменяемая коллекция данных. Его элементы нельзя изменять, у них есть номера (индексы). Можно сказать, что кортеж — это список, который нельзя изменить после создания.
# пример кортежа
tuple = ('Дата рождения', 'Родители', 'Возраст')Цикл — это алгоритм с определёнными условиями, который можно выполнять несколько раз (или бесконечно, если не указано условие для выхода из цикла).
Функция-метод .split() разбивает строки на список подстрок на основе заданного разделителя. Если разделитель не указан, по умолчанию используются пробельные символы, включая пробелы, табуляцию и переводы строки. Это удобно для разделения слов в тексте.
Метод .join() соединяет разные строки. Перед методом нужно указать элемент-строку, который будет вставляться между соединяемыми строками. Получается как .split(), только наоборот.
Map() — небольшой встроенный цикл. Эта функция принимает как аргумент другую функцию и объект, к элементам которого она поочерёдно эту функцию применяет:
# создаём функцию
def func(x):
return x**3
# создаём список
a = [1, 3, 5, 7]
# применяем к списку a функцию func внутри функции map
b = list(map(func, a))
# выведет [1, 27, 125, 343]
print(b)Enumerate() перебирает элементы объекта и присваивает каждому свой номер. По умолчанию нумерация начинается с 0, но можно задать свою. Пары «номер — элемент» кладутся в кортежи:
# создаём список
seasons = ['Весна', 'Лето', 'Осень', 'Зима']
# применяем к нему enumerate и создаём список из кортежей, начиная с номера 1
new_list = list(enumerate(seasons, start=1))
# выведет [(1, 'Весна'), (2, 'Лето'), (3, 'Осень'), (4, 'Зима')]
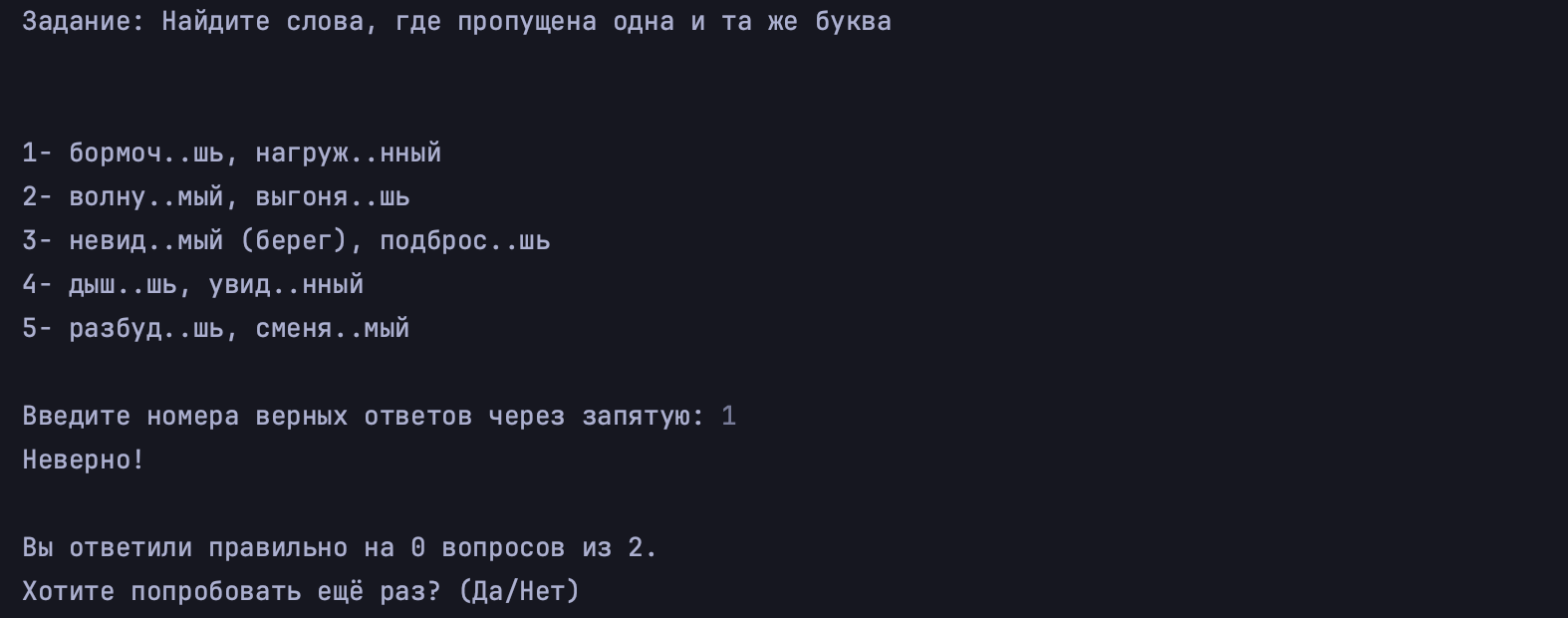
print(new_list)Так будут выглядеть итоговые тесты:
Хороший код нужно разделять на функции, каждая из которых отвечает за свою часть: читает документ с текстом, находит в тексте нужные части, выводит всё на экран. Но для наглядности мы создадим всего одну функцию, в которой по очереди будем писать весь алгоритм. Так будет видно, что и в какой последовательности мы делаем.
 Делаем конвертер из Markdown в Word с сохранением форматирования
Делаем конвертер из Markdown в Word с сохранением форматирования Как сделать игру на Python бесплатно
Как сделать игру на Python бесплатно Делаем тетрис на Python
Делаем тетрис на Python Создаём на Python скрипт, который делает из простого текстового файла .txt вордовский файл .docx
Создаём на Python скрипт, который делает из простого текстового файла .txt вордовский файл .docx Пишем на Python тесты для проверки знаний
Пишем на Python тесты для проверки знаний Добавляем графический интерфейс программе для учебных тестов
Добавляем графический интерфейс программе для учебных тестов Работа с файлами в Python: полное руководство по open(), readline() и записи данных
Работа с файлами в Python: полное руководство по open(), readline() и записи данныхПодключаем модули
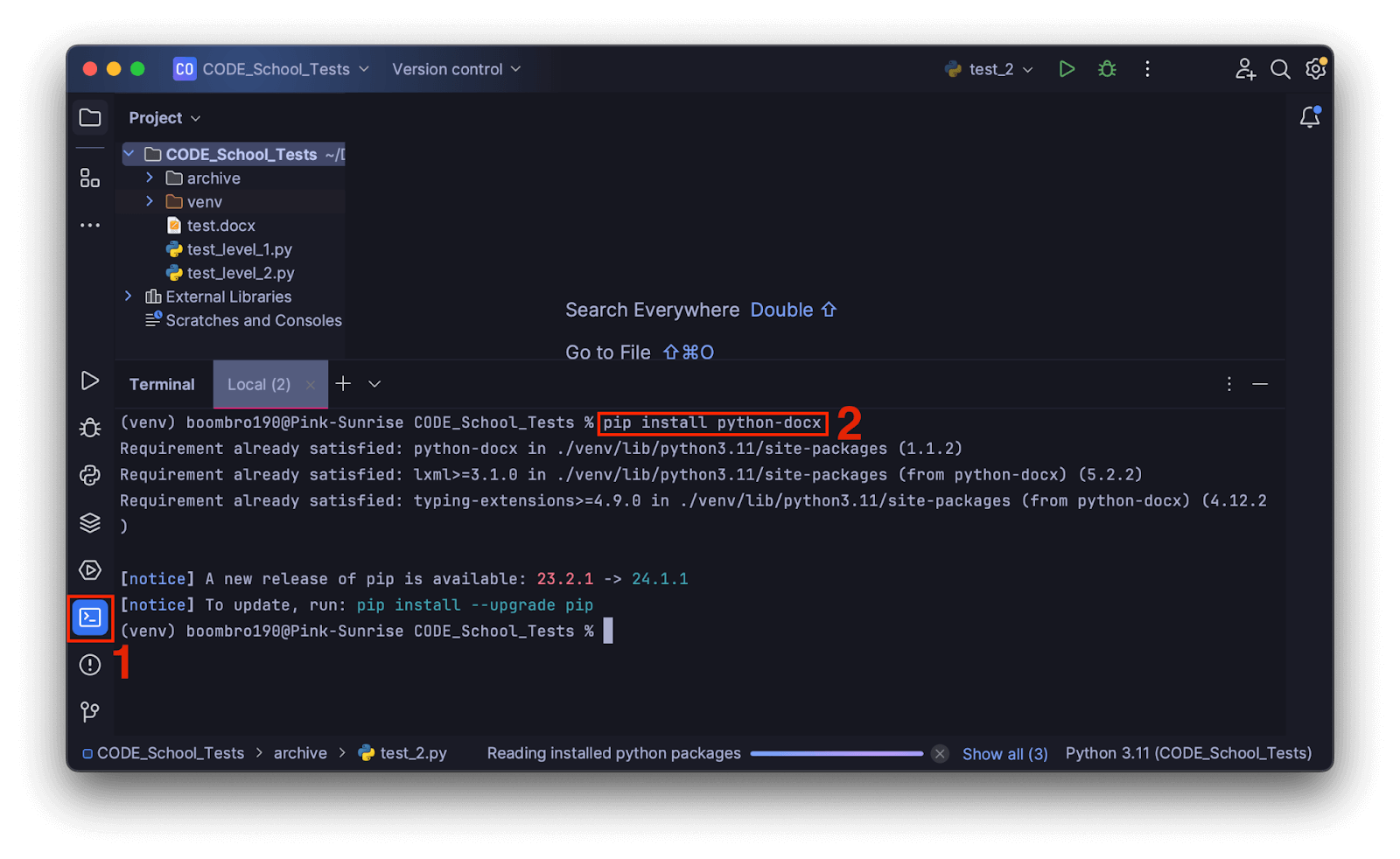
Сначала скачаем и подключим библиотеку для работы в Word:
pip install python-docx
Если пишете код в текстовом редакторе, это нужно сделать и в командной строке из папки проекта. Если в среде разработки — то в отдельной вкладке терминала.
После установки библиотеку нужно добавить в проект. Нам нужна только часть возможностей этой библиотеки — модуль Document. Заодно сразу импортируем встроенные модули re, random и time, которые не нужно предварительно скачивать:
# подключаем модуль Document библиотеки docx
from docx import Document
# подключаем модуль re
import re
# подключаем модуль random
import random
# подключаем модуль time
import timeЗагружаем тесты в документ Word
Текстовый вордовский файл у нас уже есть. Положим его название в переменную и укажем, что это именно документ Word:
document = Document('test.docx')Теперь Python видит все абзацы в этом документе. Нам нужно сделать из этих абзацев одну большую строку, чтобы потом из неё выбрать вопросы и ответы по нашим требованиям. Для этого нам понадобится генератор списков, к которому мы подключим метод строк .join():
text = "\n".join([para.text for para in document.paragraphs])Давайте разберём этот код подробнее:
Document.paragraphsв конце строки — это абзацы нашего документа (все, какие есть). Мы перебираем их, то есть запускаем по документу цикл.- Из каждого абзаца мы берём текст — за это отвечает часть
para.text in para. Необязательно использовать название переменнойpara, можно дать ей любое имя. - При выполнении кода
[para.text for para in document.paragraphs]генератор списка создаст список, элементами которого будут строки с текстами абзацев. - Мы добавляем к этому списку метод
“\n”.joinи соединяем все элементы в одну большую строку, разделив их символом\n— он означает пустую строку.
Пишем регулярное выражение
Регулярные выражения — это составные шаблоны-формулы, с помощью которых мы ищем нужные выражения в тексте. Самый простой пример использования регулярного выражения — поиск на странице или в тексте с помощью сочетания клавиш Ctrl + F. Чтобы найти все совпадения в тексте, мы указываем в поле поиска нужные символы — это и есть регулярное выражение.
Регулярные выражения можно настраивать. Механизмов настройки много, так что мы перечислим основные:
- Нужные символы. Можно указать конкретный символ или определить более общее условие, например «найти все буквы, кроме а, б и в».
- Позиция искомых символов, количество и другие характеристики. Можно указать число повторов фрагмента или в каком месте слова или строки его искать.
- Границы регулярного выражения. Программа может искать совпадения до первого попавшегося, по всему тексту или по другому заданному условию.
Чтобы создать регулярное выражение, нужно выбрать один из методов модуля re. Нам понадобится метод compile, который позволит записать наше выражение в отдельную переменную:
pattern = re.compile('Задание.+?(?=Варианты ответов)'
'|Варианты ответов.+?(?=Правильные ответы)'
'|Правильные ответы.+?(?=Задание)', re.DOTALL)Вот что означает такой шаблон:
- У нас есть три условия для поиска, шаблон сработает на любом из них. Все три части разделяются между собой вертикальной чертой
|, которая означает «или». - Каждое условие начинается со слова или слов, с которых начинается наш искомый фрагмент:
Задание,Варианты ответов,Правильные ответы. .+?означают любой символ (точка), повторяющийся любое количество раз (знак +), пока не встретится следующая часть шаблона (вопросительный знак).- Вторая половина условий выглядит так: (
?=Варианты ответов), (?=Правильные ответы) и (?=Правильные ответы). Это значит, что, как только программа видит эти слова, она сохраняет всё, что нашла до этого, и переходит к следующей части регулярного выражения. re.DOTALL— установка, которая говорит поиску не останавливаться на переносах строк.
Наше выражение будет искать сначала текст, который начинается со слова «Задание» и заканчивается перед словами «Варианты ответов». Второй фрагмент будет содержать варианты ответов, третий — правильные из них. В конце документа должно быть слово «Задание». Это нужно, чтобы код зафиксировал последний блок с правильными ответами.
Каждое совпадение по шаблону даёт нам один новый элемент. Мы добавим их в список, а потом отсортируем. Для этого понадобится ещё один метод регулярных выражений findall для поиска по всему тексту:
rough_tests = pattern.findall(text)Теперь у нас есть список rough_tests, внутри которого элементы всегда идут в одной последовательности: задание, варианты ответов, правильные ответы. Чтобы они не перемешались, разделим задания по блокам. Получится ещё один список, внутри которого вопросы к тестам будут храниться как списки второго уровня: в каждом из них будет по три элемента.
Мы будем сохранять в новый список result_tests по 3 элемента из rough_tests. Для этого сначала возьмём индексы первых трёх элементов, потом вторых и будем повторять, пока не закончатся элементы в старом списке.
result_tests = [rough_tests[i:i + 3] for i in range(0, len(rough_tests), 3)]Сейчас в rough_tests каждый элемент — это блок задания с текстом, вопросами и ответами. Перемешаем блоки, чтобы выдавать их в случайном порядке:
random.shuffle(result_tests)Пишем основную функцию
Пройдёмся по коду и будем делать всё по очереди в одной большой функции. Сначала создадим саму функцию:
def main():Чтобы считать количество ответов, объявим две переменные — для правильных ответов и для всех:
right_answers = 0
all_questions = 0Почти всё дальше мы напишем внутри тела цикла, который будет перебирать блоки заданий. Мы будем обрабатывать каждое задание и переходить к следующему:
for block in result_tests:Делаем вывод ответов в случайном порядке
Варианты ответов хранятся в виде одной строки, в начале которой стоит название блока. Нам нужны только сами варианты, и при этом они должны выводиться на экран в случайном порядке.
Если сейчас вывести строку с ответами на экран, она будет выглядеть так:
Варианты ответов:
- предложение №1 – бессоюзное сложное предложение, двоеточие ставится, потому что вторая часть указывает на причину того, о чём говорится в первой части;
- предложение №2 – простое предложение с обобщающим словом при однородных членах, поэтому ставится двоеточие;
- предложение №3 – односоставное безличное;
- предложение №4 – простое, ничем не осложнено;
- предложение №5 – простое, осложнено обособленным определением
Варианты ответов переносятся на новые строки, а это означает, что между ними находится символ-литерал \n. При выводе его не видно.
Чтобы сделать новый список с ответами, напишем такое:
variants = block[1].replace('Варианты ответов:', '').replace('\n', '').split(';')Вот что здесь происходит:
- Выбираем строку с ответами по индексу 1 — он означает второй элемент списка.
- Заменяем слова «Варианты ответов» на пустую строку.
- Заменяем все литералы
\nна пустые строки, потому что больше они не понадобятся. - Разбиваем строку в местах, где стоит точка с запятой. Это важно, поэтому в файле Word все варианты ответов должны заканчиваться ею или любым другим символом, который мы укажем в скобках после слова
split().
Получился новый список с ответами. Их порядок можно перемешать, но сначала нужно как-то отметить правильные, чтобы потом проверить ответ пользователя.
У нас есть строки с правильными ответами. Сейчас они хранятся в каждом блоке по индексу 2 и выглядят так:
Правильные ответы: 1, 2, 4
Нам нужно получить из строки множество. Для этого преобразуем её:
old_answers = set(map(int, block[2].split(":")[1].strip().split(", ")))Разберём эту строку кода:
- Разбиваем строку в месте двоеточия.
- Получается список из двух элементов — берём его правую часть по индексу 1.
- Разбиваем эту правую часть в местах, где стоит символ запятой.
- Получается список из чисел, записанных строками. У нас не
1, 2, 4, а‘1’, ‘2’, ‘4’. - Каждую строку трансформируем в число с помощью функции
int. - Новый список из чисел преобразуем во множество функцией
set.
Пронумеруем наши варианты ответов. К каждому варианту будет привязан номер, начиная с 1:
indexed_variants = list(enumerate(variants, start=1))Ответы сейчас хранятся как кортежи вида (1, ‘- волну..мый, выгоня..шь’). Перемешиваем варианты:
random.shuffle(indexed_variants)Теперь ответы в списке могут выводиться в случайном порядке, но у каждого ответа сохранился старый номер, по которому его можно проверить.
Выясним, где правильные ответы в новом перемешанном списке:
new_correct_answers = {new_index for new_index, (old_index, variant)
in enumerate(indexed_variants, start=1)
if old_index in true_old_answers}Разберём этот фрагмент подробнее:
- У нас есть список со старыми номерами ответов
old_answers. - Когда мы идём по списку
indexed_variants, мы ещё раз нумеруем каждый кортеж. Теперь ответы выглядят как(4, (1, ‘- волну..мый, выгоня..шь’)). Здесь 1 — это старый индексold_index, а 4 — новый индексnew_index. - Этот кортеж можно проверить: если старый индекс лежит в старом перечне правильных ответов
old_answers, то новый индекс нужно добавить в новое множество правильных ответовnew_correct_answers.
Теперь для любого перемешанного списка ответов есть множество, где указано, какие ответы верные.
Номера в ответах можно удалить, оставляем только текст:
new_variants = [var for num, var in indexed_variants]Выводим задание и вопрос
Тексты задания хранятся по индексу 0, его мы и выводим для каждого блока:
print(block[0])Показываем на экране все ответы, заодно нумеруя их:
for i, variant in enumerate(new_variants):
print(f'{i + 1}{variant}')Просим пользователя ввести номер ответа через запятую, записываем его в строку и сразу создаём множество ответов пользователя:
# просим ввести ответ
user_answers = input("\nВведите номера верных ответов через запятую: ")
# создаём множество из ответа пользователя
user_answers_set = set(map(int, user_answers.split(',')))Проверяем, равны ли множество ответа пользователя и множество правильных ответов. Если равны, увеличиваем счётчик правильных ответов right_answers на 1. И в любом случае увеличиваем на 1 счётчик всех ответов all_questions.
После каждого ответа пишем результат и включаем задержку на 1 секунду, чтобы было время прочесть сообщение.
# проверяем, совпадают ли множества ответов пользователя и множество правильных ответов
if user_answers_set == new_correct_answers:
# увеличиваем счётчик правильных ответов
right_answers += 1
print("Верно!\n")
# даём секунду прочесть результат
time.sleep(1)
else:
print("Неверно!\n")
# даём секунду прочесть результат
time.sleep(1)
# увеличиваем счётчик всех ответов
all_questions += 1Когда вопросы закончились, выводим финальный результат и предлагаем пройти тест ещё раз:
# отчитываемся о результатах пройденного теста и предлагаем пройти ещё раз
print(f'Вы ответили правильно на {right_answers} вопросов из {all_questions}.'
f'\nХотите попробовать ещё раз? (Да/Нет)')
# ждём, что ответит пользователь
one_more_test = input('')
# запускаем тест повторно, если пользователь отвечает 'Да'
if one_more_test == 'Да':
print()
main()Что дальше
В следующий раз мы разложим код по функциям и добавим к тестам графический интерфейс, как в приложениях с мнемокарточками.
# подключаем модуль Document библиотеки docx
from docx import Document
# подключаем модуль re
import re
# подключаем модуль random
import random
# подключаем модуль time
import time
# создаём файл документа Word
document = Document('test.docx')
# берём все абзацы документа и добавляем
# в одну строку, разделяя переносами на новые строки
text = "\n".join([para.text for para in document.paragraphs])
# создаём регулярное выражение, которое ищет все части
# текста между словами 'Задание', 'Варианты ответов' и 'Правильные ответы'
pattern = re.compile('Задание.+?(?=Варианты ответов)'
'|Варианты ответов.+?(?=Правильные ответы)'
'|Правильные ответы.+?(?=Задание)', re.DOTALL)
# создаём список, где идут вопросы, потом варианты ответов, потом правильные ответы
rough_tests = pattern.findall(text)
# создаём список из блоков по 3 элемента: вопросы, потом варианты ответов, потом правильные ответы
result_tests = [rough_tests[i:i + 3] for i in range(0, len(rough_tests), 3)]
# перемешиваем блоки
random.shuffle(result_tests)
# создаём одну функцию, внутри которой выполняются тесты
def main():
# создаём счётчик правильных ответов
right_answers = 0
# создаём счётчик всех ответов
all_questions = 0
# перебираем список из перемешанных блоков с заданиями
for block in result_tests:
# создаём список вариантов ответов: это второй элемент
# в каждом блоке, его индекс равен 1
variants = block[1].replace('Варианты ответов:', '').replace('\n', '').split(';')
# получаем множество с правильными ответами из строки с правильными ответами:
# это третий элемент в каждом блоке, его индекс равен 2
old_answers = set(map(int, block[2].split(":")[1].strip().split(", ")))
# уменьшаем номера ответов на 1, чтобы компьютер понимал, какой ответ на самом деле правильный
# нумеруем варианты ответов
indexed_variants = list(enumerate(variants, start=1))
# перемешиваем их
random.shuffle(indexed_variants)
# делаем новый список без номеров из перемешанных ответов
new_variants = [var for num, var in indexed_variants]
# определяем новые правильные ответы: для этого проверяем, какой ответ на каком месте стоял раньше
new_correct_answers = {new_index for new_index, (old_index, variant)
in enumerate(indexed_variants, start=1)
if old_index in old_answers}
# выводим на экран первый элемент каждого блока: текст задания
print(block[0])
# выводим на экран второй элемент каждого блока поэлементно:
# это наш перемешанный список с ответами
for i, variant in enumerate(new_variants):
print(f'{i + 1}{variant}')
# просим ввести ответ
user_answers = input("\nВведите номера верных ответов через запятую: ")
# создаём множество из ответа пользователя
user_answers_set = set(map(int, user_answers.split(',')))
# уменьшаем все элементы множества на 1, чтобы ответ мог совпадать со множеством правильных ответов
# проверяем, совпадают ли множества ответов пользователя и множество правильных ответов
if user_answers_set == new_correct_answers:
# увеличиваем счётчик правильных ответов
right_answers += 1
print("Верно!\n")
# даём секунду прочесть результат
time.sleep(1)
else:
print("Неверно!\n")
# даём секунду прочесть результат
time.sleep(1)
# увеличиваем счётчик всех ответов
all_questions += 1
# отчитываемся о результатах пройденного теста и предлагаем пройти ещё раз
print(f'Вы ответили правильно на {right_answers} вопросов из {all_questions}.'
f'\nХотите попробовать ещё раз? (Да/Нет)')
# ждём, что ответит пользователь
one_more_test = input('')
# запускаем тест повторно, если пользователь отвечает 'Да'
if one_more_test == 'Да':
print()
main()
main()










