


Самая сложная игра в мире — так официально называется аркадная игра, где вы должны пройти от одного безопасного места к другому. Сложность в том, что ваша скорость намного меньше, чем скорость движущихся препятствий. Когда они вас настигают — всё обнуляется и игра начинается сначала. Если хотите попробовать свои силы — попробуйте.
Выглядит это так:
Наш старый знакомый Эван (он же CodeBullet) написал нейронку, которая научилась выигрывать в эту игру, и снял об этом видео. Если знаете английский, лучше посмотрите видео, там довольно забавно всё происходит. Для остальных мы приготовили текстовую версию того, что происходит у Эвана:
Пишем саму игру
Чтобы можно было управлять красным квадратиком и адекватно реагировать на происходящее, можно пойти двумя путями: написать отдельную нейронку для распознавания того, что происходит на экране (это очень сложно), или написать саму игру, чтобы сразу отдавать нейронке все данные (это гораздо проще). Эван выбрал вариант с игрой, поэтому вот какие правила нужно было учесть:
- за границы выходить нельзя;
- нужно дойти квадратиком от одной безопасной зелёной зоны до другой;
- синие шарики постоянно отскакивают от стен и не сбиваются с курса;
- красный квадратик движется гораздо медленнее, чем синие шарики;
- когда шарик касается квадратика — вы проиграли, начинайте сначала.
Поэтапно это выглядело вот так:
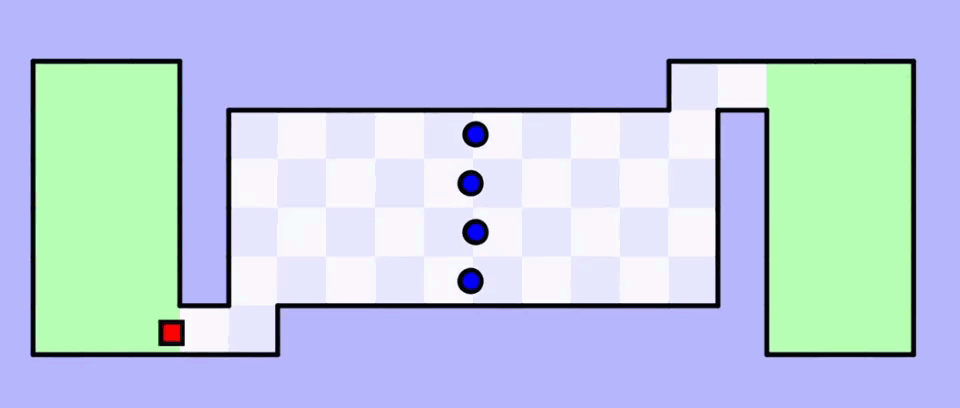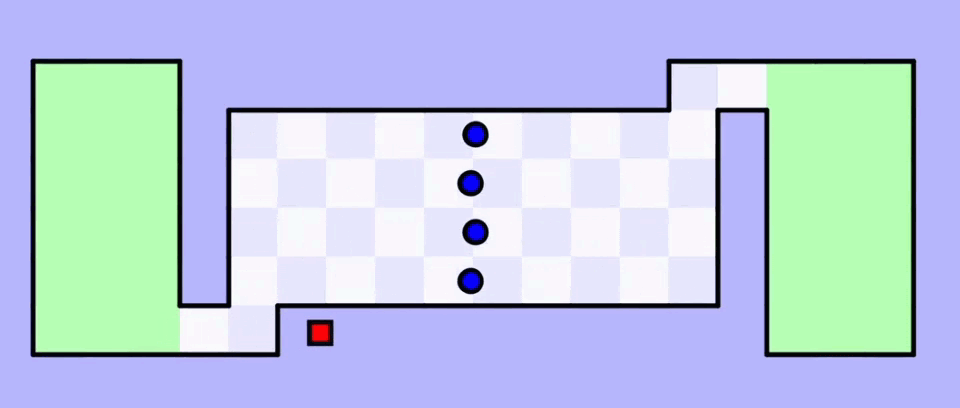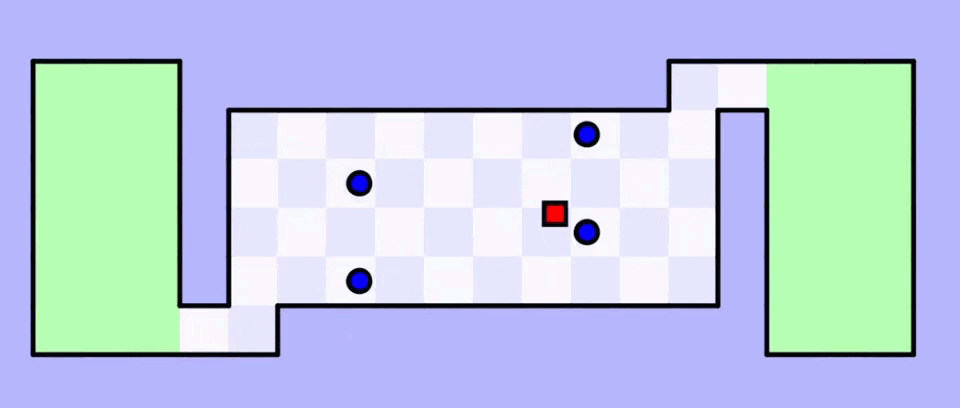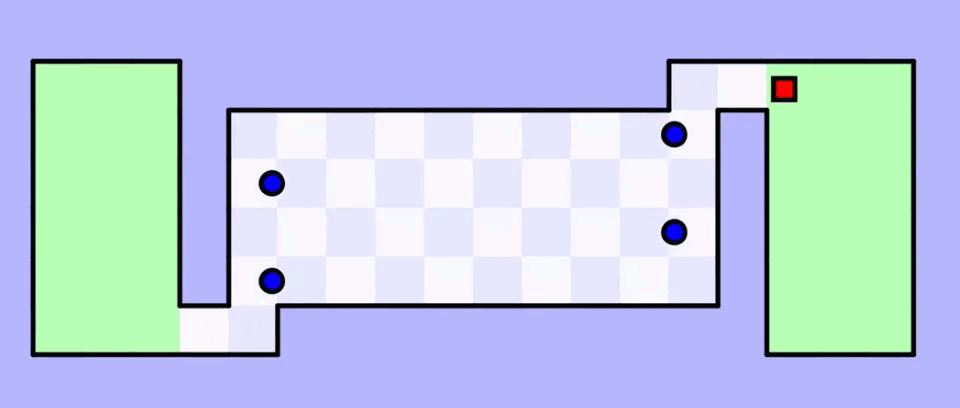
После всех нужных исправлений у нас получилась игра, в которую можно играть самому, а можно прикрутить к ней нейросеть, которая всё сделает за нас. Этим сейчас и займёмся.
Пишем нейронку
Сначала Эван взял за основу стандартный алгоритм:
- В каждом поколении есть множество квадратиков, которые действуют одинаково.
- Каждый квадратик может пойти куда угодно.
- Те квадратики, которые дольше всего проживут, берутся за основу для следующего поколения нейросети.
- Так, шаг за шагом, у нас получится алгоритм, в котором будут самые жизнеспособные квадратики.
Посмотрим, что из этого получится:

Проблема в том, что в этой игре важно не прожить квадратику как можно дольше, а дойти до противоположной зелёной части. То есть если алгоритм не поменять, все квадратики будут жить в зелёной зоне бесконечно долго, но выиграть точно не получится.
Новый алгоритм — дойти как можно дальше
Поменяем алгоритм на такой:
- У нас снова есть поколения квадратиков, каждое из которых опирается на лучших из предыдущего.
- В следующий этап проходит только тот квадратик, который прошёл дальше остальных (даже если ему пока просто повезло).
- Но для начала нужно, чтобы квадратики научились выходить из зелёной зоны.
С такими параметрами всё стало интереснее — квадратики научились выходить из безопасной зоны. Чтобы обучение шло продуктивнее, на старте у квадратиков есть только 10 ходов, но с каждым поколением количество доступных ходов увеличивается на 5. Получается, что каждое новое поколение может ходить дальше, чем предыдущее, учитывая прошлый опыт. Кажется, это то, что нужно.
Почувствуйте разницу между поколениями и посмотрите, как они выбираются из безопасной зоны:

Квадратики научились выходить из зелёной зоны, но они пока не знают, как вести себя с синими шариками. Нужна новая ступень обучения.
Избегаем синих шариков
Будем учить так: столкновение с синим шариком — это плохо, и в нейронку уходит соответствующий сигнал, мол, постарайся так не делать. Проблема в том, что квадратик слишком медленный, чтобы реагировать сразу, поэтому ему нужно научиться заранее прогнозировать своё поведение и стараться избегать столкновения.
Это самый долгий этап обучения, поэтому мы его немного ускорим и упростим — будем показывать только один квадратик (лучший в каждом поколении) и только основные этапы. Поехали.
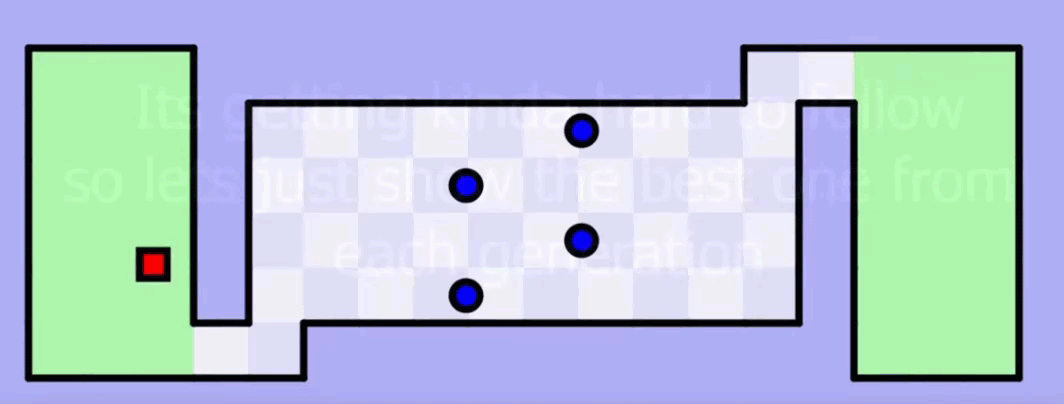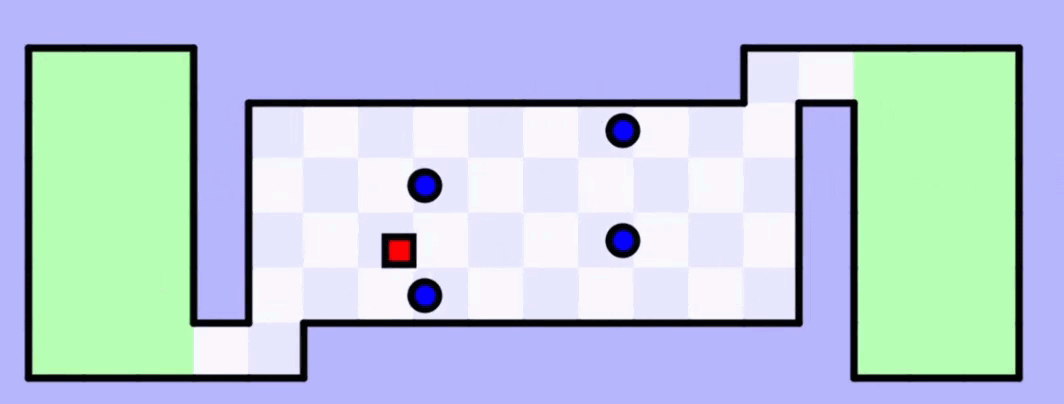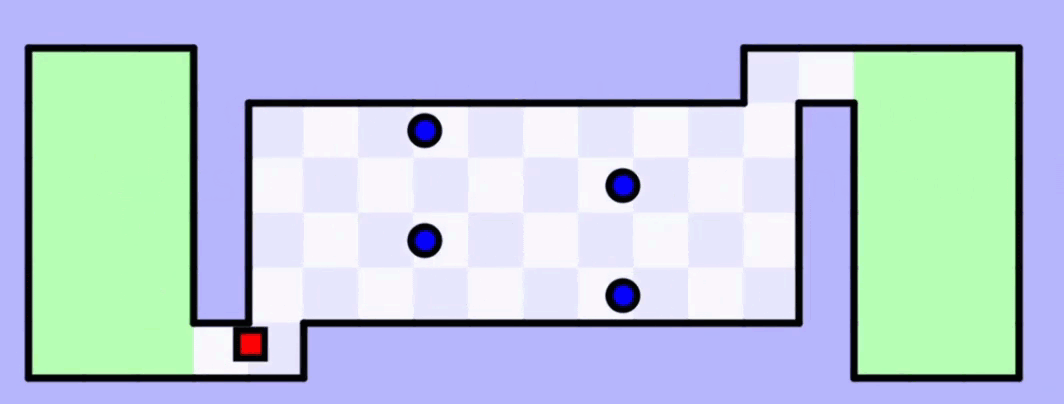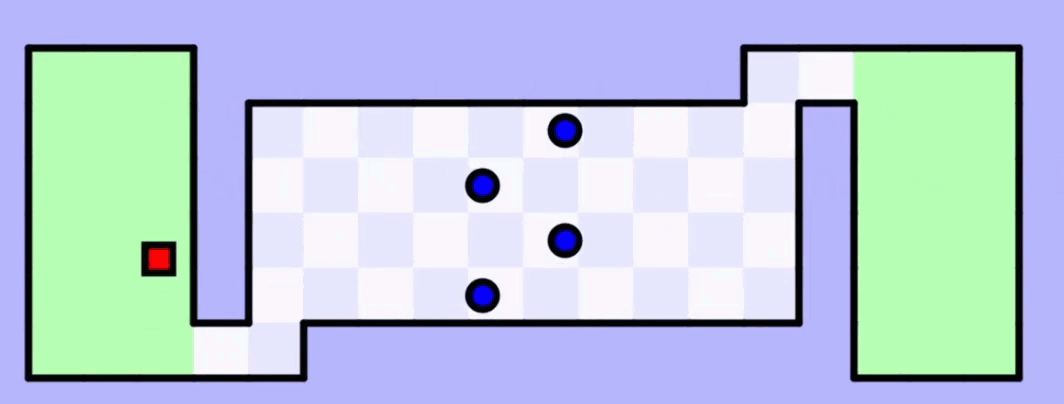
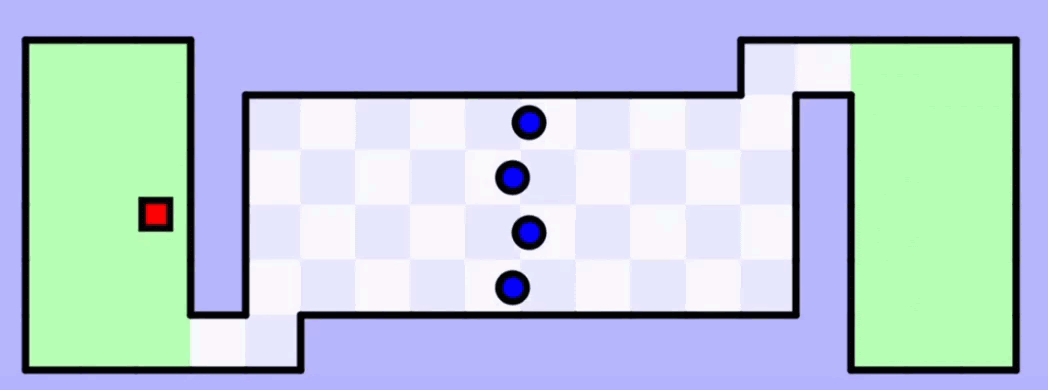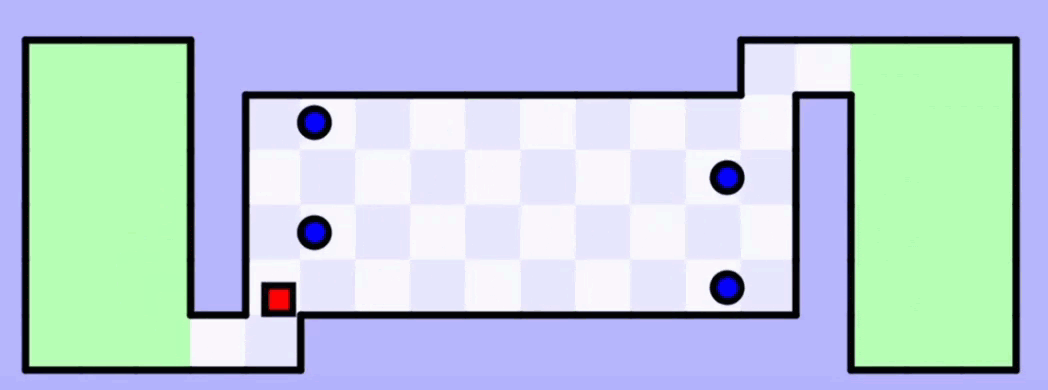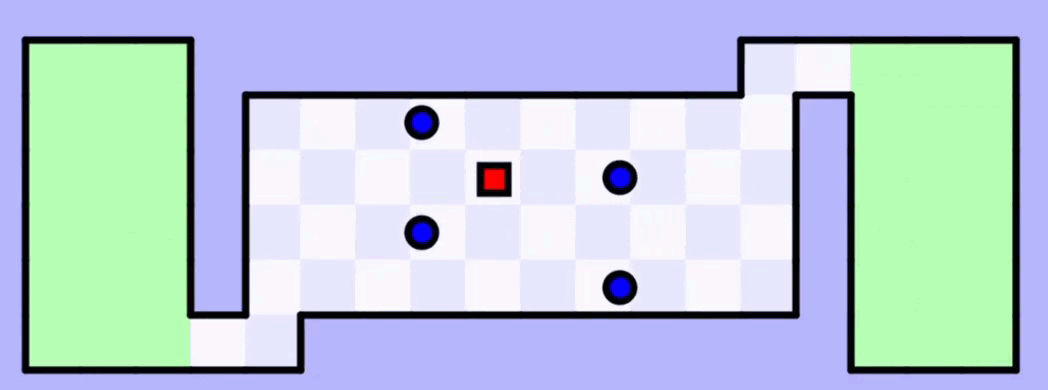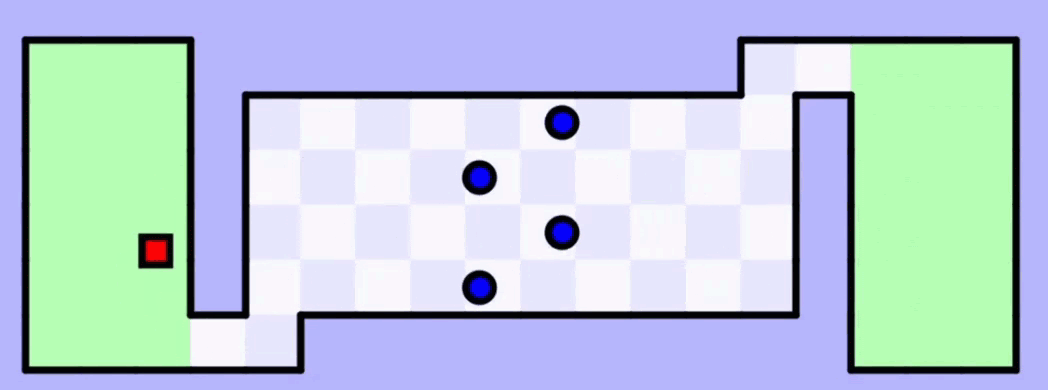
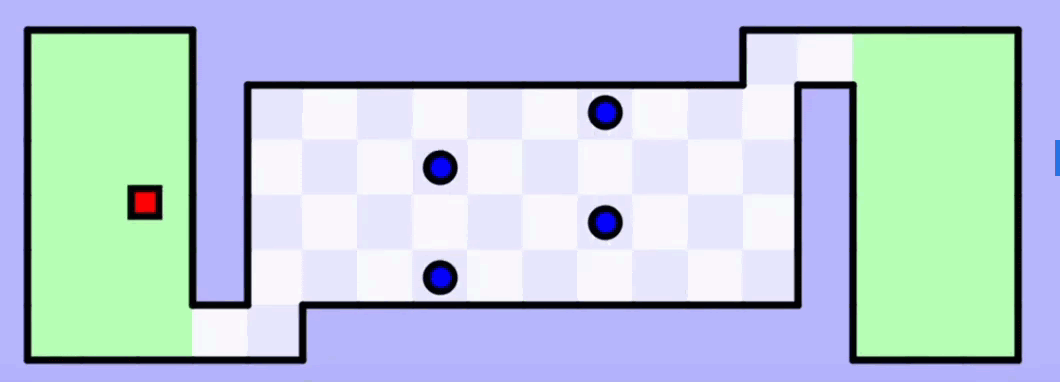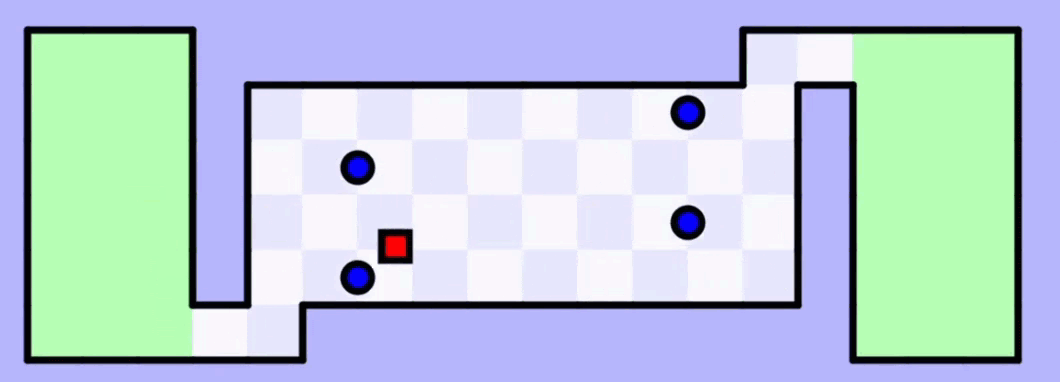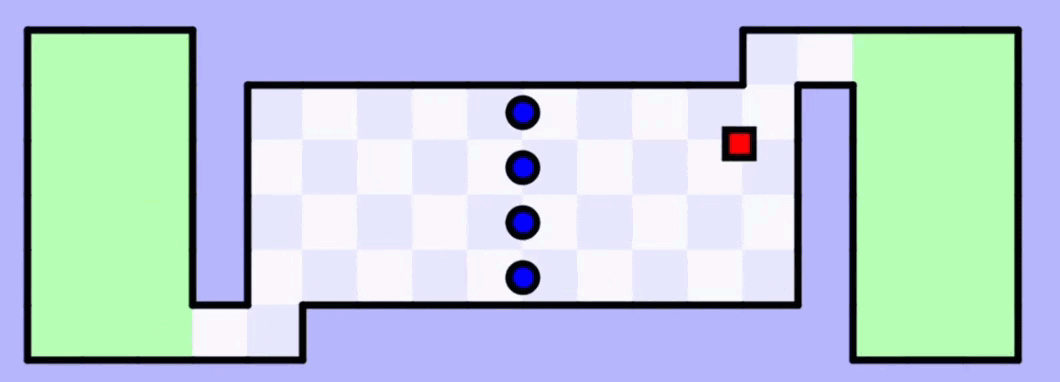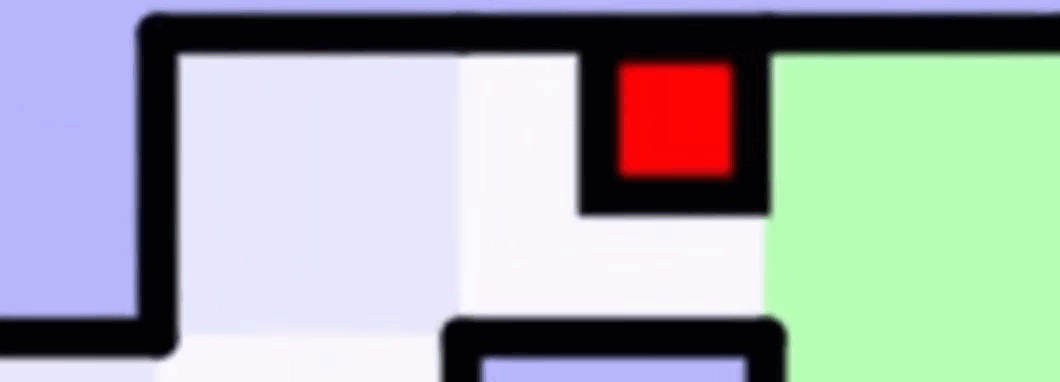
На 50-й итерации обучения искусственный интеллект наконец-то довёл квадратик до второй зелёной зоны. Но это не идеальная модель — чтобы закрепить результат, нужно её прогнать таким же образом ещё много-много раз.
Вывод такой: не всегда изначальный параметр — правильный. Если бы мы не поменяли алгоритм с долгожительства квадратиков на преодоление препятствий, то ничего бы не получилось. Но каждая такая ошибка — шаг на пути к верному решению. Помните это и не сдавайтесь.
Что дальше
Дальше мы попробуем написать эту игру сами.
А потом напишем нейронку, которую тоже научим сами.
Круто? Круто! Поэтому подписывайтесь, делитесь с друзьями и не пропускайте новые проекты.














