При работе программисты редко пишут весь код с нуля, даже если это небольшой учебный проект. Обычно разработчики подключают инструменты с уже готовыми функциями, которыми можно пользоваться, — библиотеки и фреймворки.
Сегодня рассказываем про 7 библиотек на Python и чем они интересны и полезны.
Эта статья — больше про теорию. Если вам интереснее попрактиковаться в разработке, посмотрите наши учебные проекты:
О чём рассказываем сегодня
Сначала вспомним, что такое библиотеки: это написанные другими разработчиками функции, которые можно добавить в свою программу. Например, если мы работаем над сложными математическими проектами, можно сделать так:
- Собрать все сложные формулы, которые мы используем.
- Каждую формулу вынести в отдельную функцию — мы подаём на вход данные, а функция возвращает готовый результат.
- Собрать эти функции в одну библиотеку.
- Подключить её к своему проекту.
- И теперь, когда нам в очередной раз понадобится формула, мы просто вызываем её из подключённой библиотеки, а не пишем её код заново в новом проекте.
Вот пример, как работает определение среднего арифметического через готовую функцию библиотеки NumPy:
average = numpy.mean([1, 2, 3, 4, 5])А вот так выглядит код для подсчёта среднего арифметического без использования готовых возможностей библиотеки:
def calculate_mean(values):
total = 0
count = 0
for value in values:
total += value
count += 1
return total / count if count != 0 else None
average = calculate_mean([1, 2, 3, 4, 5])Python — самый популярный и универсальный язык, который существует много лет, поэтому библиотек для него написано много, больше 137 000 (и это только те, которые зарегистрированы). Про все мы сегодня рассказать не успеем, но про некоторые полезные — расскажем. Заодно вспомним некоторые подробности о языке и программировании вообще.
Установка библиотек
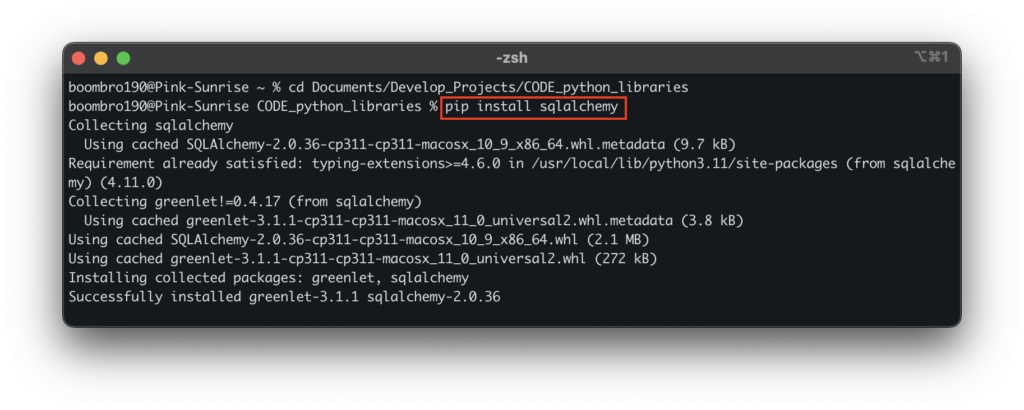
Чтобы работать с библиотеками, их нужно установить командой в терминале pip install. Например, pip install sqlalchemy.
Это можно сделать в командной строке:

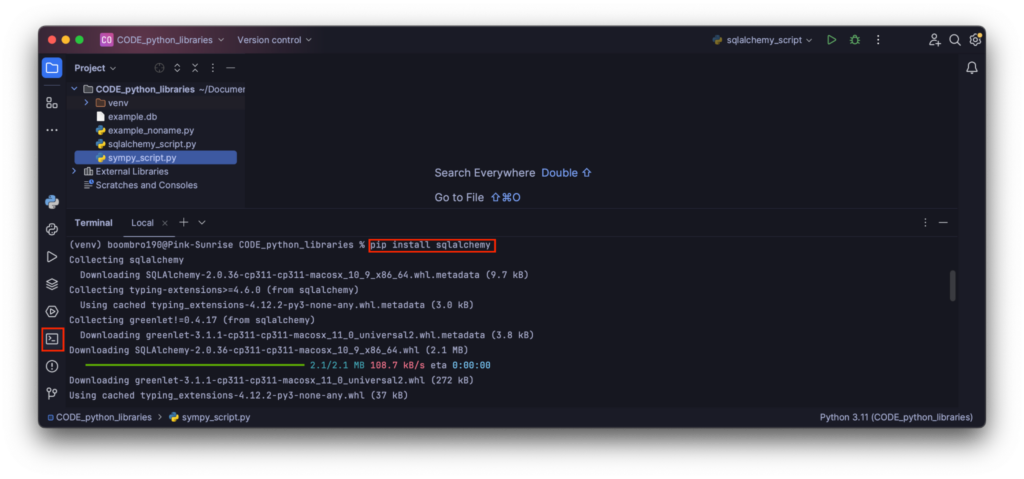
Или прямо в среде разработки IDE на вкладке с терминалом:







SQLAlchemy
SQLAlchemy — это ORM-инструмент для работы с базами данных. ORM (object relational mapping, или объектно-реляционное отображение) — технология, которая позволяет работать с базами данных как с обычными классами и объектами.
Обычно с базами данных работают через синтаксис конкретной базы и язык запросов SQL. С ORM нужно учить гораздо меньше нового синтаксиса, и такой подход сильно упрощает работу с данными. А ещё со всеми библиотеками можно работать через один и тот же код.
Если не добавлять новую базу данных, Python по умолчанию будет создавать таблицы в своей встроенной базе SQLite.
Так будет выглядеть создание таблицы в базе данных, настройка нужных полей-ячеек, запись данных и запрос в таблицу. Попробуйте найти тут классические SQL-запросы :)
# импортируем подключение к базе данных, колонки и типы данных для колонок
from sqlalchemy import create_engine, Column, Integer, String
# импортируем базовый класс для создания таблиц баз данных
from sqlalchemy.ext.declarative import declarative_base
# импортируем модуль для сессий работы с данными
from sqlalchemy.orm import sessionmaker
# создаём базу данных SQLite и подключение к ней
engine = create_engine('sqlite:///example.db')
# сохраняем шаблон таблицы базы данных в переменную
Base = declarative_base()
# определяем модель таблицы базы данных по шаблону SQLAlchemy
class User(Base):
# название таблицы базы данных
__tablename__ = 'users'
# создаём колонку id
id = Column(Integer, primary_key=True)
# создаём колонку c именем
name = Column(String)
# создаём колонку с возрастом
age = Column(Integer)
# создаём таблицу в базе данных
Base.metadata.create_all(engine)
# открываем сессию для взаимодействия с базой данных
Session = sessionmaker(bind=engine)
session = Session()
# добавляем запись с новым пользователем
new_user = User(name="Alice", age=30)
session.add(new_user)
session.commit()
# запрашиваем данные из таблицы
users = session.query(User).all()
for user in users:
print(user.name, user.age)После запуска консоли мы сразу увидим результат:
Alice 30
Кроме удобства, ORM добавляют безопасности, потому что проверяют и очищают входные данные. Это предотвращает внедрение хакерского кода через вредоносные SQL-запросы для управления базой данных и получения доступа к важной информации. Такая атака называется SQL-инъекцией.
С другой стороны, использование ORM ставит разработчика в зависимость от синтаксиса конкретного ORM и языка программирования. Если после Python вы начнёте программировать на Rust, использовать ту же ORM не получится. А ещё возможностей объектно-реляционного отображения не всегда достаточно для работы с по-настоящему сложными профессиональными запросами, например для обработки больших данных в Data Science.
Плюсы SQLAlchemy те же, что и у большинства ORM:
- Удобно работать с базами данных.
- Усиливает защиту базы данных.
Минусы:
- Сложные запросы проще написать на SQL.
- Ограничивают разработчика своим синтаксисом и языком программирования, с которым работают.
SymPy
Полезный инструмент для сложной математики.
SymPy позволяет решать алгебраические уравнения в символьном виде. Поясним, чтобы было понятнее.
- Алгебраические уравнения — уравнения с многочленами, когда в выражении есть символы x, y, z и другие (те самые многочлены), значения которых нужно найти. Вот пример уравнения с тремя неизвестными:

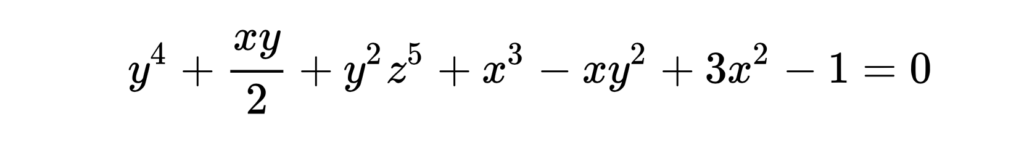
- Символьный вид значит, что мы можем записать уравнения в привычном виде, то есть используя переменные.
- Решение уравнений в символьном виде позволяет записать уравнение, а библиотека сама подумает и найдёт решения.
Вот пример решения простого уравнения x² − 4 = 0:
# импортируем модули символов, выражений и решения
from sympy import symbols, Eq, solve
# определяем символ 'x'
x = symbols('x')
# передаём в библиотеку уравнение x^2 - 4 = 0
equation = Eq(x**2 - 4, 0)
# запрашиваем решение
solutions = solve(equation, x)
# выводим решение на экран
print(solutions)В консоли получим решение:
[-2, 2]
Плюс:
- Можно решать уравнения привычным человеческим способом.
Минус:
- В работе есть проблемы с описанием типов данных — аннотациями типов.
Cookiecutter
Библиотека для работы с готовыми шаблонами проектов.
В профессиональных проектах в корневой папке лежит много файлов и других папок, которые нужно создавать в начале:
- YAML-скрипты для настройки автоматического обновления кода во всех источниках, в том числе на серверах;
- документация;
- настройки и плагины;
- автотесты;
- руководства для тех, кто хочет добавить что-то своё в проект;
- конфигурационные файлы для разных инструментов.
Шаблоны библиотеки уже хранят в себе нужные папки и некоторые готовые файлы. Нужно только подобрать нужный шаблон, скачать его через команду библиотеки, указать свои настройки и начать пользоваться. Это сильно ускоряет разработку и упрощает работу над проектами.
Вот пример одного из шаблонов с официальной страницы библиотеки:

Минус в том, что на GitHub уже тысячи шаблонов cookiecutter, и нет никаких чётких критериев, какой из них подойдёт именно под ваш проект.
Ещё иногда лучше потратить время и собрать систему самому с нуля, потому что так вы точно будете знать структуру программы и сможете настроить её так, как надо вам. С шаблоном не всегда известно, что именно делают файлы и куда посылают запросы готовые скрипты.
Pickle
Встроенная библиотека для простой сериализации и десериализации объектов.
Что это значит:
- Сериализация — процесс перевода данных в удобный для передачи формат. Обычно это последовательность байтов, которую потом легко передать по сети или между частями системы.
- Десериализация — обратный процесс, когда данные восстанавливают в исходную сложную структуру из простой последовательности.
Пример работы:
# импортируем pickle
import pickle
# создаём объект — словарь
data = {"name": "Alice", "age": 25, "city": "Wonderland"}
# сериализация: превращаем объект в байты
serialized_data = pickle.dumps(data)
# десериализация: восстанавливаем объект из байтов
deserialized_data = pickle.loads(serialized_data)
# выводим результат десериализации
print(deserialized_data)В консоли получим восстановленные данные:
{'name': 'Alice', 'age': 25, 'city': 'Wonderland'}
С этой библиотекой нужно быть осторожным. Pickle может хранить не только данные, но и код, и при десериализации этот код запускается. Но при хранении данных в двоичном формате нельзя просто открыть их и посмотреть, что в них, поэтому это может стать уязвимостью в безопасности. Если вы получаете pickle-файл, созданный кем-то другим, в нём могут быть вшиты вредные для проекта скрипты.
Плюс:
- Удобная библиотека для быстрого сжатия файлов для упрощения их передачи.
Минус:
- Может быть причиной уязвимостей, поэтому в серьёзных проектах нужно использовать с большой осторожностью.
Pygame
Библиотека для создания игр.
Это довольно мощная библиотека с широкими возможностями, с ней можно создать несложную красивую игру на привычном Python-синтаксисе.
Чтобы стать профессиональным разработчиком игр и зарабатывать на этом деньги, изучить только Python без других библиотек недостаточно. Чаще всего гейм-разработчики используют другие языки и технологии, но с pygame вполне возможно создать хорошую простую инди-игру или потренироваться в понимании общих принципов разработки игр.Если вам тоже интересно попробовать создать свою игру на Python с pygame, почитайте наши статьи о создании небольшой игры с этой библиотекой. В конце мы сделаем такое:

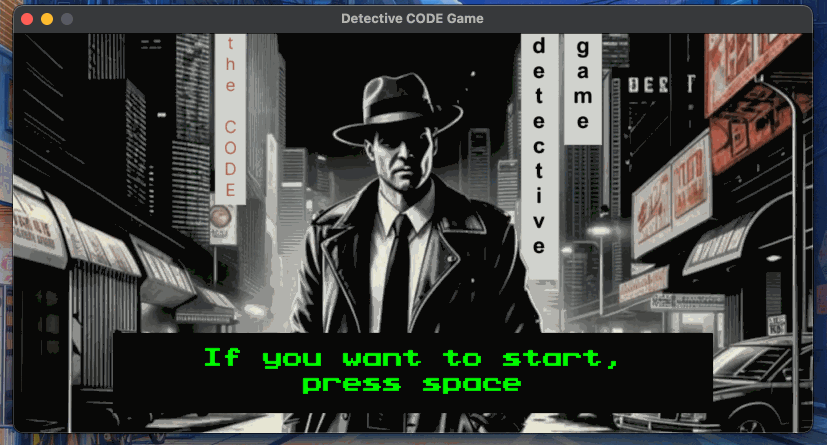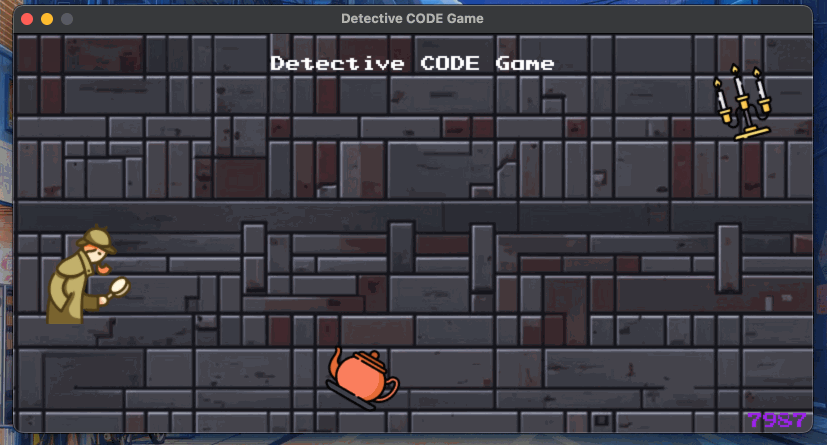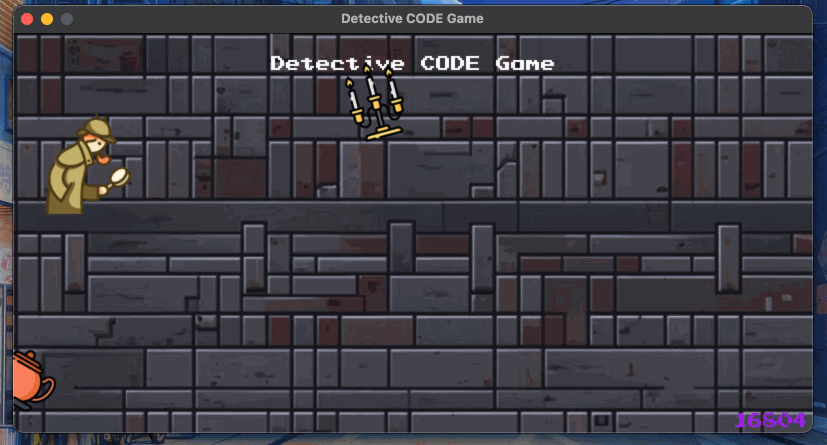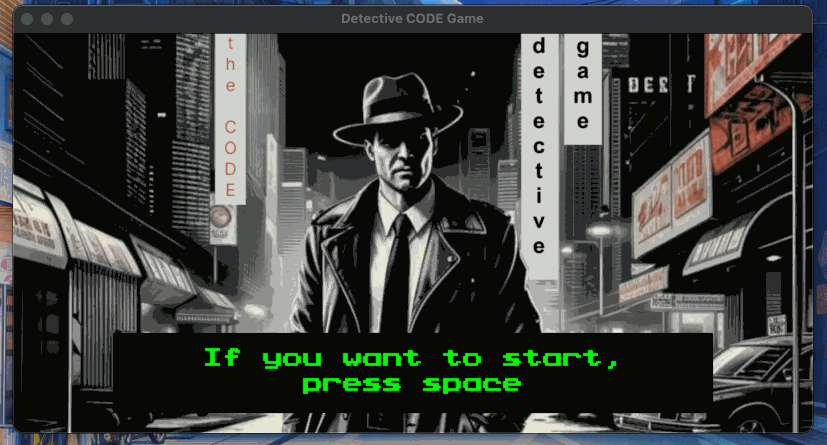
Плюс pygame:
- Можно создать свою игру уже через 1–2 дня изучения библиотеки.
Минус:
- Для серьёзного проекта одной этой библиотеки точно недостаточно (но для старта — самое то).
Missingno
Подсвечивает недостающие данные на визуализациях.
Как это работает: у вас есть набор данных, но некоторых из них не хватает. Вместо того чтобы искать их в коде или консоли, можно построить графики или диаграммы, на которых сразу будет видно, чего именно нет.
Вот пример кода — мы добавили np.nan, чтобы наглядно отметить недостающие данные:
# импортируем missingno и библиотеки для работы с данными и визуализации
import missingno as msno
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# создаём функцию
def main():
# создаём словарь с нехваткой данных
data = {
"имя": [
"Алла",
"Борис",
"Владимир",
"Галина",
"Дмитрий",
"Евгения",
"Зина",
"Игорь",
"Константин",
"Любовь",
],
"возраст": [25, 35, np.nan, 22, 40, np.nan, 33, 29, np.nan, 45],
"очки": [85, 90, np.nan, 95, 88, 76, np.nan, 80, 92, np.nan],
"рост": [165, 180, 175, np.nan, 168, 177, np.nan, 162, 170, 178],
"вес": [70, np.nan, 68, 75, 72, 80, np.nan, 64, 70, 85],
}
# помещаем словарь в датафрейм
df = pd.DataFrame(data)
# заполняем пробелы через missingno
msno.matrix(df)
# визуализируем получившийся результат
plt.show()
# запускаем функцию
main()Смотрим на график, который рисует Python. Сразу видны пробелы в данных, которых нам не хватает:

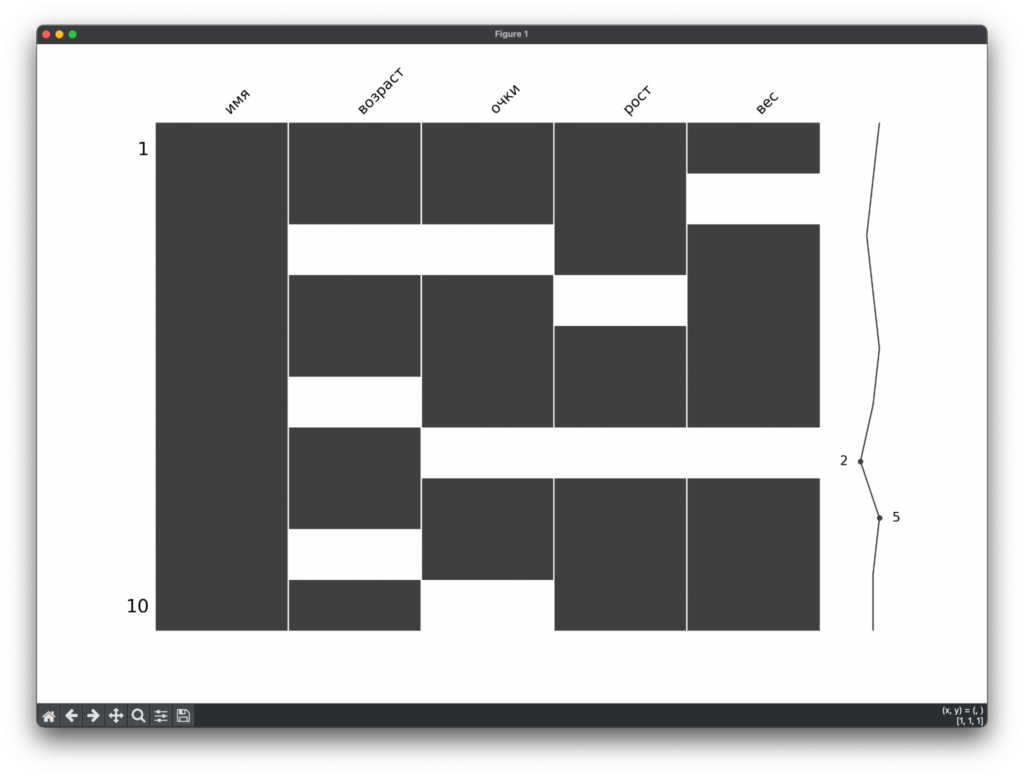


Watchdog
Инструмент для наблюдения за файловой системой.
Эта библиотека присылает уведомления, когда что-то изменилось в проекте. С ней всё можно настроить так, чтобы при изменениях в структуре проекта запускались какие-то определённые действия, или просто отслеживать изменения.
Код выглядит немного запутанно, но если разбирать его построчно, то в общих чертах становится понятно. Мы используем две главные вещи из библиотеки — обработку событий FileSystemEventHandler и наблюдателя Observer:
# импортируем модуль для управления временем
import time
# импортируем класс для обработки событий файловой системы
from watchdog.events import FileSystemEventHandler
# импортируем класс для наблюдения за изменениями в файловой системе
from watchdog.observers import Observer
# определяем класс — обработчик событий, используя класс из watchdog
class MyHandler(FileSystemEventHandler):
# метод, срабатывающий при изменении файлов
def on_modified(self, event):
# выводим сообщение с путём изменённого файла
print(f"{event.src_path} был изменён")
# основная функция
def main():
# устанавливаем параметры для наблюдения за изменениями файлов
# задаём путь к папке, за которой мы наблюдаем. "." означает текущую папку
path_to_watch = "."
# создаём объект обработчика событий
event_handler = MyHandler()
# создаём объект наблюдателя
observer = Observer()
# устанавливаем наблюдение для указанного пути,
# включая все подкаталоги (recursive=True)
observer.schedule(event_handler, path=path_to_watch, recursive=True)
# запускаем наблюдение за изменениями
observer.start()
# выводим сообщение о начале наблюдения
print(f"Ведём наблюдение за папкой {path_to_watch}... Нажмите Ctrl+C для остановки.")
try:
# оставляем скрипт запущенным, чтобы наблюдение не прерывалось
while True:
# пауза в 1 секунду, чтобы цикл не занимал процессор
time.sleep(1)
except KeyboardInterrupt:
# останавливаем наблюдатель при прерывании скрипта
observer.stop()
# дожидаемся завершения работы наблюдателя
observer.join()
# запускаем основную функцию
main()В консоли при запуске появится сообщение:
Ведём наблюдение за папкой .... Нажмите Ctrl+C для остановки.
Если попробовать что-то изменить в папке проекта, в консоли появится уведомление:
/Users/boombro190/Documents/Develop_Projects/CODE_python_libraries был изменён
Что дальше
Мы рассказали о некоторых полезных и интересных библиотеках для Python, но уместить в один материал всё полезное невозможно, поэтому в следующий раз продолжим. Подпишитесь, чтобы не пропустить продолжение.