


Помимо разработки программ, недавно в мире ИТ появилось большое направление работы с большими данными. У компаний есть множество источников данных, теперь нужно научиться извлекать из них полезные знания.
В этом руководстве — введение в эту сферу, основные понятия и разбор карьерных перспектив для тех, кто думает стать дата-сайентистом или инженером данных.
Что такое бигдата
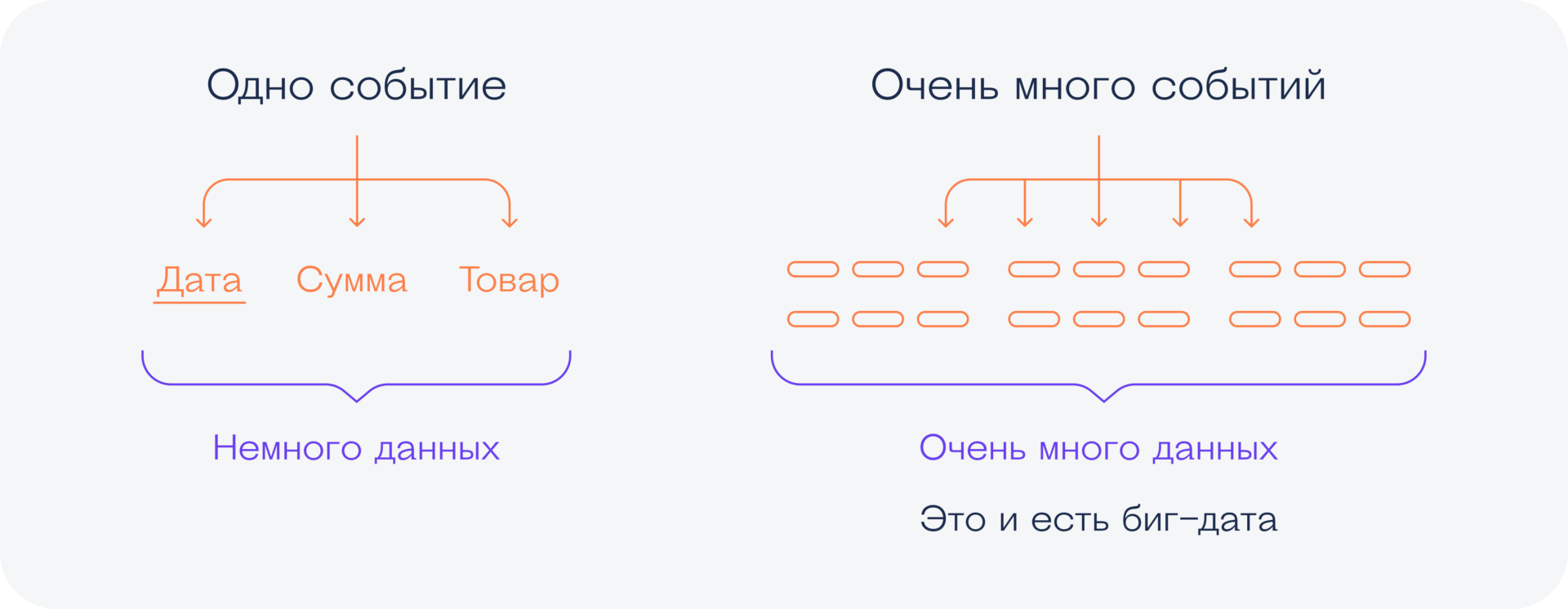
Big data, или «большие данные», — это термин, обозначающий огромные массивы данных, которые накапливаются в каких-то больших системах.
Например, человек в Москве совершает 5–6 покупок по карте в день, это около 2 тысяч покупок в год. В стране таких людей, допустим, 80 миллионов. За год это 160 миллиардов покупок. Данные об этих покупках — бигдата.
В банках какой-то страны каждый день совершаются сотни тысяч операций: платежи, переводы, возвраты и так далее. Данные о них хранятся в центральном банке страны — это бигдата.
Ещё бигдата: данные о звонках и СМС у мобильного оператора; данные о пассажиропотоке на общественном транспорте; связи между людьми в соцсетях, их лайки и предпочтения; посещения сайтов; данные о покупках в конкретном магазине; данные с шагомеров и тайм-трекеров; скачанные приложения; открытые вами файлы и программы.
Какие-то из этих данных уже накоплены и требуют анализа. Какие-то накапливаются прямо сейчас, и бизнес хочет принимать на основе этих данных правильные решения: кому что предлагать, какие продукты выпускать, какие скидки делать, как подстраивать предложение под спрос и т. д. Тут на сцену выходят специалисты по данным: сайентисты, инженеры и аналитики.
Что такое Data Science
Дата-сайентисты — люди, которые занимаются большими данными: придумывают, как получать из них полезные выводы быстро и желательно автоматически.
В каком-то смысле это аналитики — то есть вы говорите им: «Ребята, вот данные, нужно по ним получить ответ на такой-то вопрос».
Но также дата-сайентисты работают намного шире. Они должны:
- Разбираться в источниках данных.
- Понимать, как собирать данные и готовить их для анализа.
- Уметь извлекать знания из данных — как аналитики.
- Уметь автоматизировать извлечение данных и выводов — через визуализацию, алгоритмы и нейросети.
- В идеале — вообще создавать автономные системы принятия решений на основе данных, чтобы все данные собирались автоматически, а выводы поставлялись бесперебойно и не требовали участия человека.
Идеальный проект для дата-сайентиста — система рекомендация товаров на основании данных о том, как человек сидит в нашей соцсети. Представьте, сколько измерений данных можно из этого извлечь — начиная с его анкеты, заканчивая скоростью его скролла. И насколько сложно по массе всех его данных научиться автоматически отбирать нужные ему товары нужных рекламодателей. Вот это — прямо золотой пример задачи сайентиста.
Ещё пример: мы управляющая компания магазина «Пятёрочка». По всей стране у нас открыты магазины. Мы можем попросить дата-сайентиста создать такую систему, которая показывала бы, какие магазины можно безболезненно закрыть, не упав по выручке ниже определённого порога. Гипотеза в том, что некоторые «Пятёрочки» стоят слишком плотно друг к другу, а людям столько точек не нужно. Вот сайентист должен будет придумать, как постоянно и системно отвечать на этот вопрос.
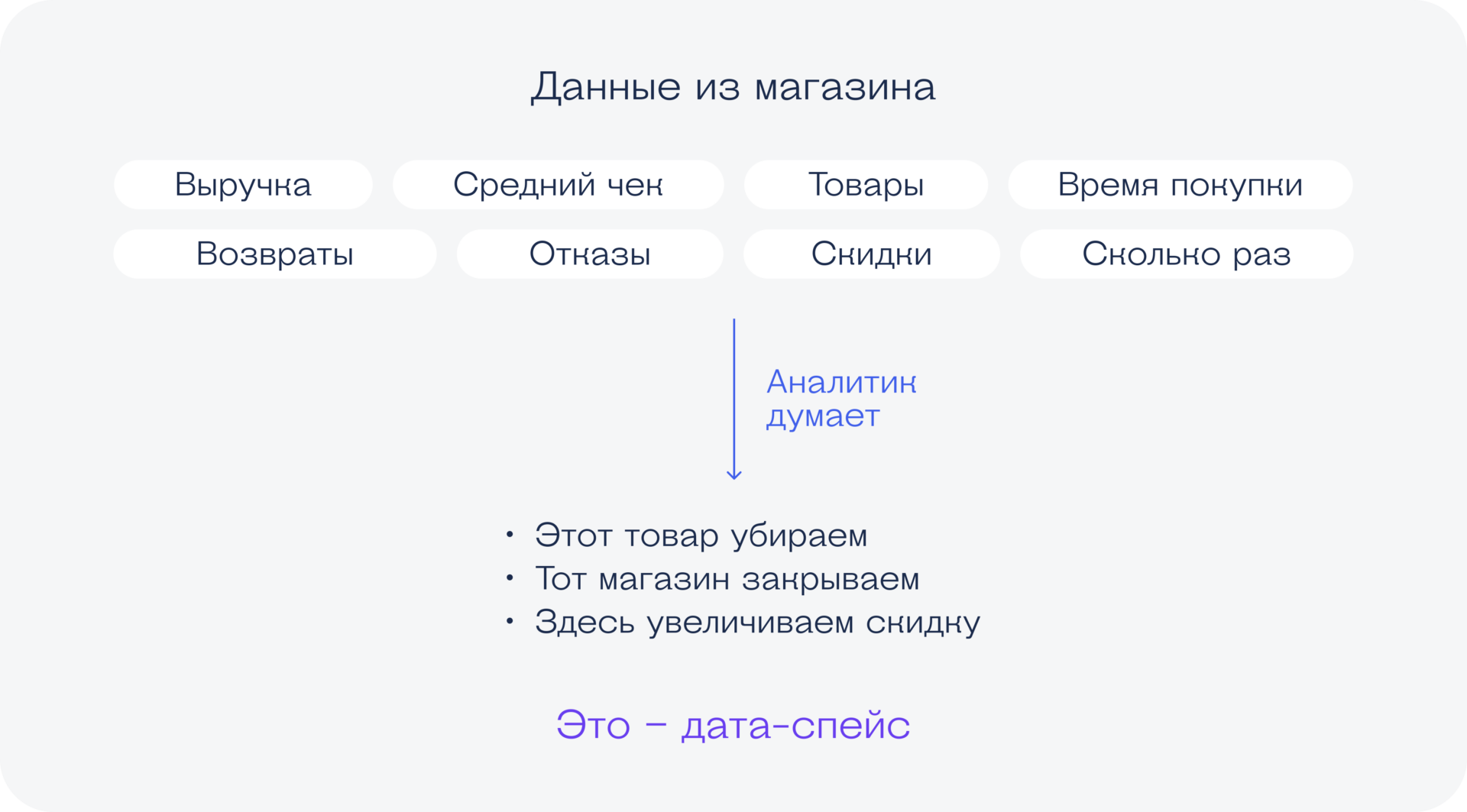
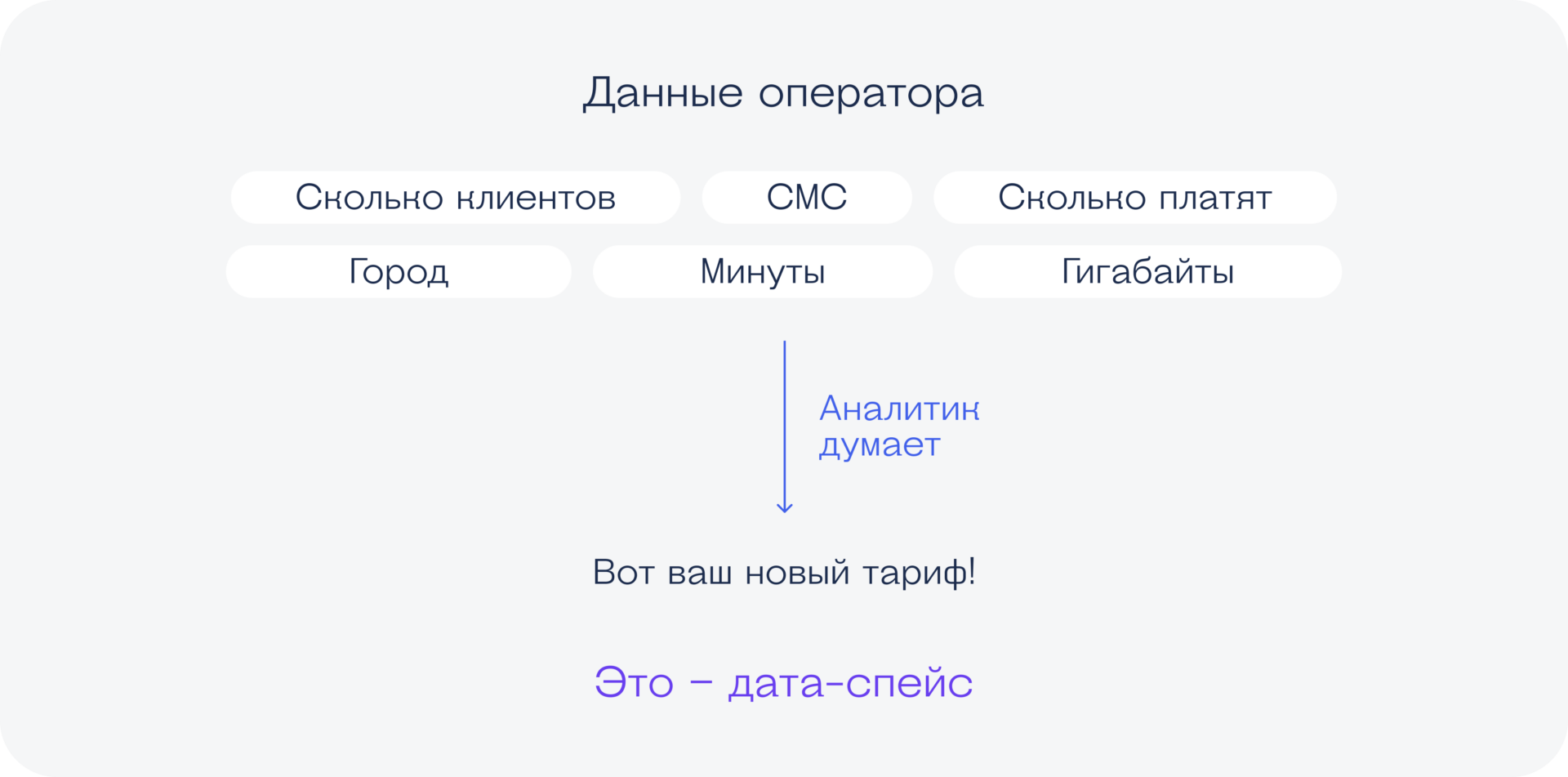
Ещё пример. Мы мобильный оператор. Мы хотим выпускать тарифы, которые опережают желания потребителей. Мы отдаём нашу клиентскую базу и данные о поведении клиентов дата-сайентисту, и тот создаёт для нас модель, которая предсказывает следующий актуальный тариф для нужных нам людей. Алгоритм как-то следит за поведением абонентов, выявляет тенденции, строит выводы: «Вот этой группе людей нужно +30 гигабайт, они за это готовы заплатить ещё 300 ₽».



Что такое нейросети и как они связаны с дата-сайенсом
Один из прорывных инструментов дата-сайентиста — нейросети. Это не единственный инструмент, но важный.
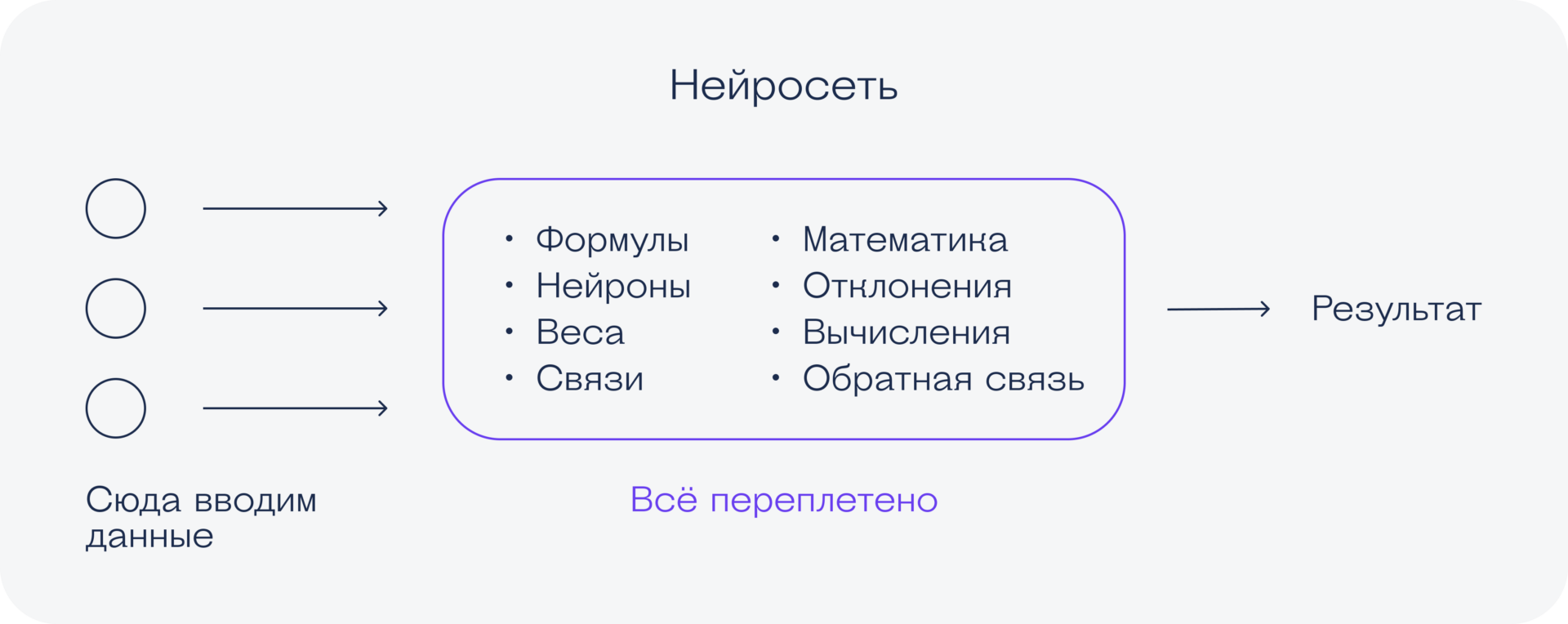
Нейросеть — это сложная база данных, в которых ячейки связаны между собой формулами. Данные поступают с одного конца базы данных, обрабатываются через множество формул и выдаются с другого конца.
Если нейронка правильно «обучена», то эти данные могут быть полезны в народном хозяйстве. Настройка этих формул — задача специалиста по машинному обучению или дата-сайентиста.
Примеры, зачем может быть полезна нейросеть для бизнеса и трудоустройства:
- На основе предыдущих покупок человека предсказать, что ему может быть интересно дальше.
- Выявить мошеннические схемы, отмывание денег, попытки взлома наших систем сложными методами.
- На основании исторических данных о погоде предсказать завтрашнюю.
- Подогнать текст, вёрстку или дизайн сайта под предпочтения и поведение конкретного клиента (автоматически).
- На основании данных о взаимодействии менеджеров и клиентов подобрать идеальные пары, чтобы клиентам было приятно звонить в вашу компанию.
Можно представить, что правильно обученная нейросеть — это очень быстрый прогнозист. Он ошибается в 2% случаев, но в 98% случаев он заменяет живого человека, который строит гипотезы и предполагает будущее.
Где научиться писать нейросети:
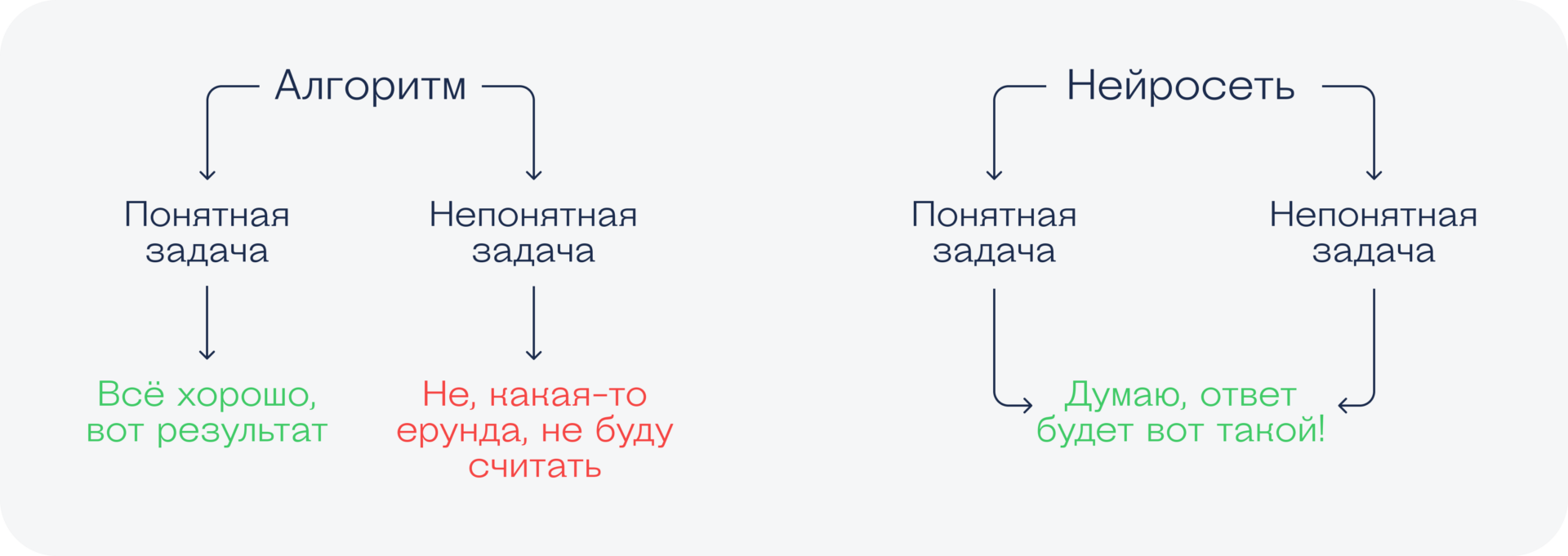
Чем нейросети отличаются от обычных алгоритмов
Вот самое простое отображение структуры нейросети. Слева ячейки ввода данных, справа ячейки вывода данных, а между ними — какой-то скрытый слой, в котором нейросеть совершает свои математические вычисления. Пока что это может быть непонятно, но мы ещё расскажем об этом отдельно.
В классических алгоритмах разработчики сразу прописывают правильную последовательность действий, которые дают какой-то предсказуемый результат. Например, разработчик пишет программу для расчёта площади квартиры по чертежу, и там пошагово описаны все действия: умножь, сложи, вычти и т. д. Если посмотреть на этот алгоритм, будет понятно его устройство, в него можно внести изменения.
Нейросетям вместо алгоритмов дают много заранее правильно решённых задач. Например, десять тысяч планов квартир с уже прописанными площадями. И нейросеть начинает угадывать, какой результат от неё ожидают. Отдельный алгоритм говорит ей, правильно она угадала или нет, и со временем она учится угадывать всё более правильно.
По ходу обучения у нейросети формируются связи, которые позволяют ей угадывать полезный результат. Какие это связи, никто не понимает: мы можем их пронаблюдать, но не всегда можем понять принцип, по которым они формируются.
Что такое Machine Learning
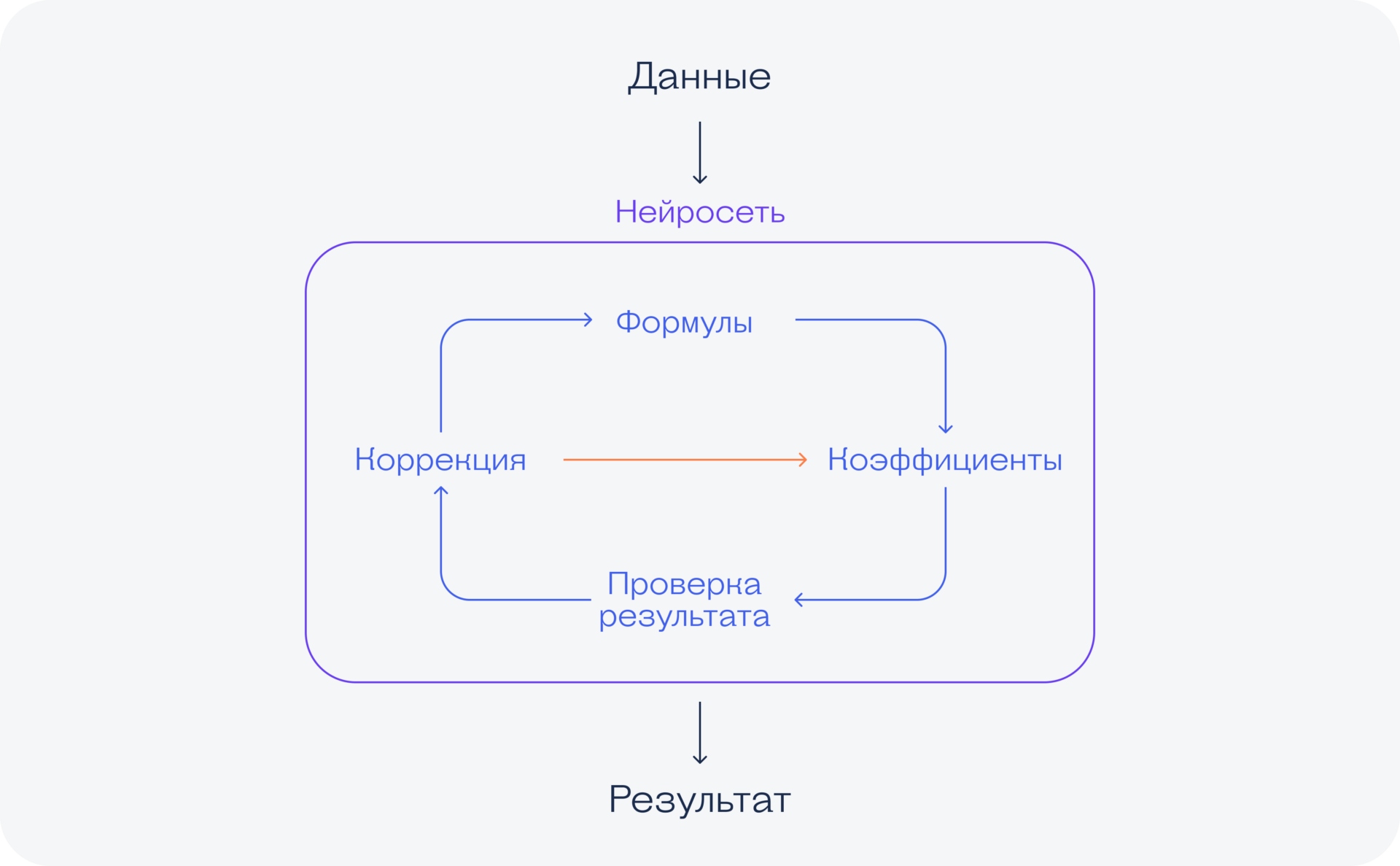
Machine Learning («машинное обучение») — это когда нейросеть учат работать правильно, чтобы она могла заранее отличить хороший свой ответ от плохого и дать только хороший ответ.
Суть обучения нейросети — задать нужные формулы, чтобы при вводе определённого типа данных мы получали достаточно качественные результаты вычислений.
Обучение происходит на большом массиве данных: закидываем в нейросеть много задач с одного конца и много правильных ответов к этим задачам с другого конца. С помощью специального математического колдовства нейронка учится выдавать правильные ответы не только на эти задачи, но и на другие похожего вида.
Почему о дате и нейросетях всегда говорят через запятую
Эти сферы действительно тесно переплетены. Нейросети очень нужны для решения человеческих задач по автоматизации, а для работы нейросетей нужно очень много данных. В свою очередь, благодаря нейросетям можно извлекать новые данные о поведении людей и работе механизмов. И так по кругу: больше данных, больше нейросетей, ещё больше данных и т. д.
В итоге аналитики, сайентисты и дата-инженеры тянут на себе всё это хозяйство: и собирают данные, и автоматизируют, и обучают, и тестируют. Всё рядом, всё похоже, всё пересекается.
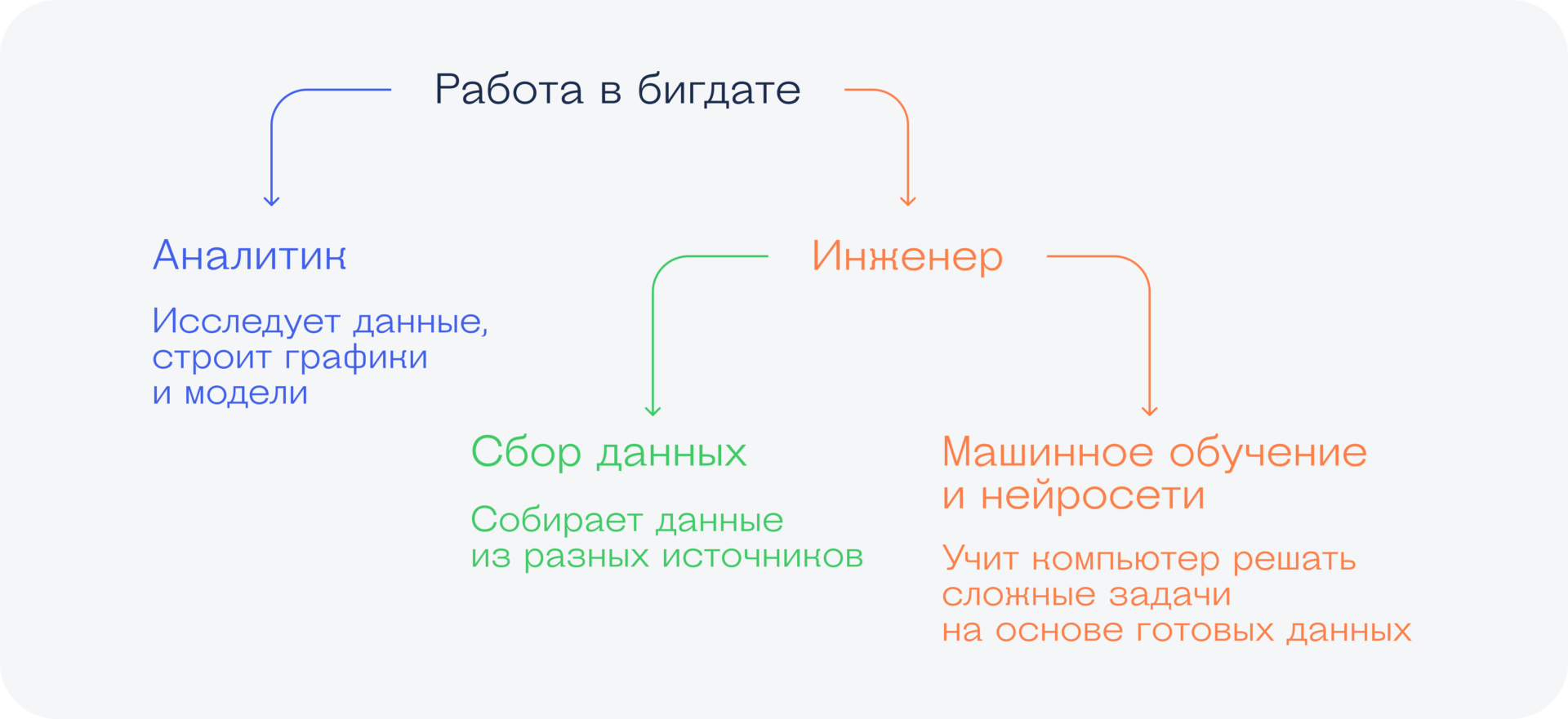
Профессии в бигдате
Бигдата — это несколько направлений в ИТ. У них общая основа, но различаются инструменты и подход к работе. И хотя люди постоянно переходят из одной сферы в другую, а термины ещё не устоялись до конца, всё равно для порядка нужно как-то их разделить:
- Аналитики работают с уже собранными данными — приводят их в порядок, анализируют, строят графики и модели. Иногда говорят, что аналитик занимается разовыми задачами.
- Инженеры и дата-сайентисты занимаются сбором данных и машинным обучением. Можно с некоторой уверенностью сказать, что инженер больше про сбор, а сайентист про обучение, но это очень условное разделение.
Чем отличаются аналитики от дата-сайентистов
На самом деле разделение — чистая условность. Но можно представить так:
- Работа дата-сайентиста в том, чтобы создать механизм обработки и анализа данных. Это может быть алгоритм на Python, обученная нейросетевая модель, какой-то механизм получения и очистки данных.
- Работа аналитика в том, чтобы задать правильные вопросы и получить полезные ответы. Для этого он может использовать механизмы, созданные сайентистами, или какие-то ещё инструменты.
- Если не лезть в машинное обучение, то аналитик и дата-сайентист — это очень похожие профессии. Но если речь про машинное обучение, то там обычно дата-сайентисты знают гораздо больше математики и намного лучше разбираются в сложном программировании.
Чем занимаются аналитики данных
Задача аналитика — обработать большой массив информации и сделать на его основе какие-то выводы. Примеры:
- какой товар и по каким причинам продаётся лучше всего в такой-то период;
- в какое время лучше всего привозить свежую выпечку, чтобы она не залёживалась на прилавке до вечера;
- какие метрики влияют на прибыль и выручку от клиента, а какие нет;
- какую промоакцию провести в этом месяце, чтобы она имела смысл для клиента и была коммерчески целесообразной.
В общем случае — «Какое решение лучше всего принять, исходя из имеющихся данных?»
Чтобы презентовать результаты своей работы в понятном виде, аналитики используют сервисы визуализации данных, например Tableau. А чтобы получать результаты — техники и методы анализа; чем дольше работаешь, тем больше в них вникаешь.
Типичный запрос для аналитика в торговой компании будет звучать так: «Нам кажется, что нужно показывать клиентам из Сочи рекламу надувных игрушек для бассейна, а жителям из Сибири — рекламу лыж. Реклама и того и другого будет стоить нам 50 млн рублей в год. Есть какие-то данные, чтобы обосновать или опровергнуть эту гипотезу? Помоги нам не потерять эти 50 млн». Можно сказать, что запрос очевидный и интуитивно понятный, но готовы ли мы поставить 50 млн на свою интуицию?
Аналитик помогает посмотреть на разные вопросы в разрезе реальных данных, а не интуитивных догадок. Это могут быть данные из прошлого или даже прогнозы, построенные на каких-то моделях. Главное — аналитик не подгоняет данные под нужные выводы, а показывает реальность: «Вот о чём говорят данные».
Где научиться:
Чем занимаются инженеры по сбору данных
Инженер — это технический специалист, который помогает решить вопросы обработки, сбора и хранения данных так, чтобы всем остальным это было удобно, данные не потерялись и вообще всё было хорошо.
Эту работу может сделать и аналитик, и инженер машинного обучения, но иногда сбор становится отдельной задачей. В этом случае инженер:
- пишет скрипт, который будет собирать информацию из нужных источников;
- настраивает базу данных;
- следит за правильностью собранных данных и корректирует скрипт, если что-то идёт не так;
- фильтрует данные, чтобы в базу попадало меньше мусора.
Для этого достаточно общих знаний из бигдаты плюс знание API того сервиса, откуда забираем данные. Но этому всё равно нужно учиться — сложно будет прийти в такой проект, если знаешь только базы данных или у тебя начальные навыки программирования на Python.
Где научиться:
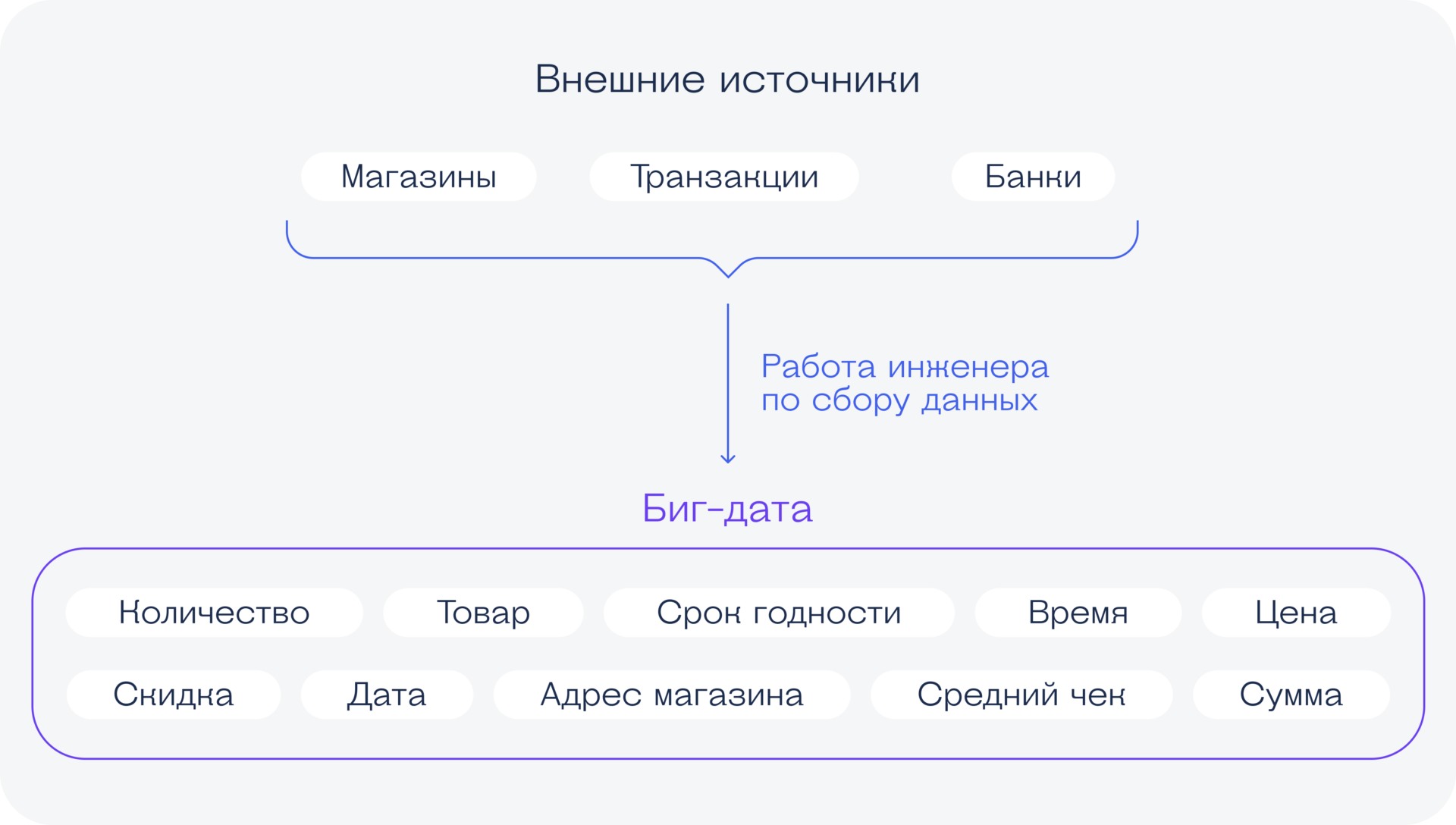
Что делают специалисты по Data Science
У этих ребят задачи технически намного сложнее, потому что они чаще всего работают с нейросетями — обучают их или программируют самостоятельно. Для этого надо знать много математики:
- теорию вероятностей,
- статистику,
- математическую логику,
- матан,
- численные методы,
- работу с векторами и матрицами,
- теорию рядов.
Кроме этого, будущим дата-сайентистам дают углублённые знания Python и учат их работе с нейросетями. Это значит — много программирования, библиотеки, фреймворки, API, базы данных, тестирование и облачные вычисления. В итоге всё это позволяет разработчикам создавать нейросети, заниматься компьютерным зрением, искусственным интеллектом, голосовыми помощниками и вообще быть впереди компьютерной науки.
Где научиться:
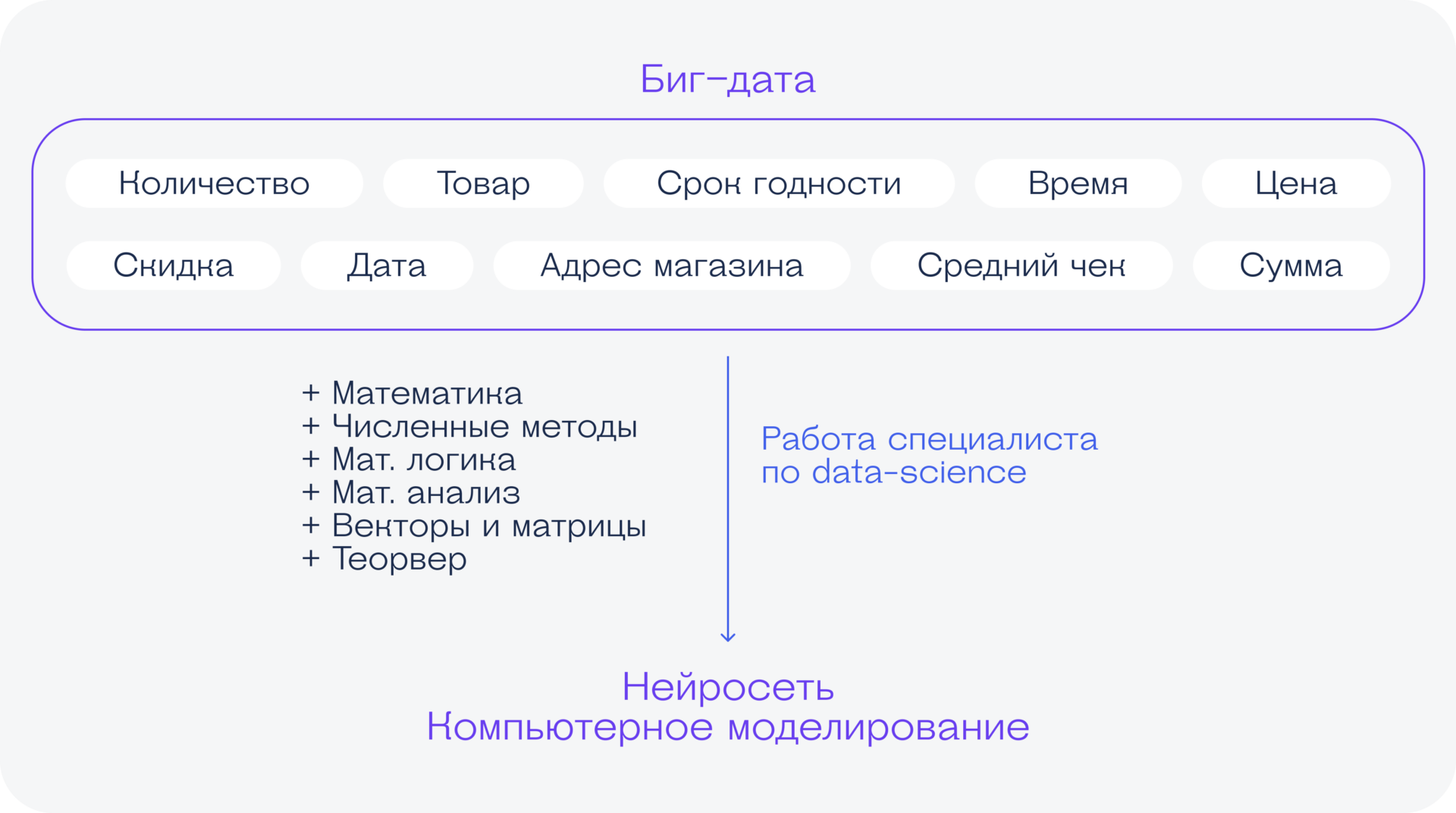
Что нужно знать, чтобы полноценно заниматься бигдатой
Вот начальный список навыков, знаний и умений, которые нужны для старта в работе.
Математическая логика, линейная алгебра и высшая математика. Без этого не получится построить модель, найти закономерности или предсказать что-то новое. Для начала работы аналитиком можно знать это на базовом уровне.
Есть те, кто говорит, что это всё не нужно и главное — писать код и красиво делать отчёты, но они лукавят. Чтобы обучить нейронку, нужна математика и формулы; чтобы найти закономерности в данных — нужна математика и статистика; чтобы сделать отчёт на основе большой выборки данных — ну вы поняли. Математика рулит.
Знание машинного обучения. Работа дата-сайентиста — анализ данных огромного размера, и вручную это сделать нереально. Чтобы было проще, они поручают это компьютерам. Поручить такую задачу — значит настроить готовую нейросеть или обучить свою. Поручить программисту обычно это нельзя — слишком много нужно будет объяснить и проконтролировать.
Программирование на Python и R. Python — идеальный язык для машинного обучения и нейросетей. На нём можно быстро написать любую модель для первоначальной оценки гипотезы, поиска общих данных или простой аналитики.
R — язык программирования для статического анализа. Если вам нужно прикинуть, как лайки на странице зависят от количества просмотров или до какого места читатель гарантированно долистывает статью (чтобы поставить туда баннер), — R вам поможет. Но если вы не знаете математику — не поможет.
Умение получать данные. Не всем везёт настолько, что они сразу получают готовые наборы данных для обработки. Чаще всего нужно самим выяснить, где, откуда, как и сколько брать данных. Здесь обычные программисты им уже могут помочь — спарсить сайт, выкачать большую базу данных или настроить сбор статистики на сервере.
Визуализация. Ещё один важный навык в этой профессии — умение наглядно показать результаты работы. Какой толк в графиках, если никто, кроме автора, не понимает, что там нарисовано? Задача дата-сайентиста — представить данные наглядным образом, чтобы зрителю было легче сделать нужный вывод.
Минимальная база для старта в машин-лёрнинге
Если из всех направлений вы планируете выбрать машинное обучение, то вот что нужно знать на старте — без этого не получится полноценно разобраться в предмете:
Python — основной язык программирования нейросетей и анализа данных. Сначала изучите его, потом беритесь за всё остальное.
Библиотеки машинного обучения — Pytorch и TensoFflow. С ними будет в сто раз легче, чем делать всё самому с нуля.
Виды и различия нейросетей: свёрточные, рекуррентные, цепи Маркова и все остальные. Не бывает «просто нейросети» — каждая сеть построена по определённой архитектуре и решает конкретные задачи.
Векторы и матрицы. Большинство нейросетей — это работа с матрицами, большими и маленькими, простыми и сложными, бинарными или комплексными.
Очистка данных. Если за основу взять непроверенные, неподготовленные и неочищенные данные, то нейросеть будет работать плохо и выдавать неправильные решения.
Почему школьной математики не хватит для полноценного дата-сайенса
В школе нам дают базу и основу, чтобы мы имели представление о предмете и могли посчитать разные несложные штуки. Для работы с бигдатой этого недостаточно: у больших данных есть свои математические законы, которые нужно знать.
Кроме обычной математики, хорошему дата-сайентисту нужно знать много из институтского курса физмата: матан, теорию вероятности, дифференциальное исчисление и прочие направления математики. Даже если вы не пишете нейросети, для работы аналитиком тоже требуется высшая математика — например, выяснить, с каким отклонением коррелируют данные на графике с результатами теоретических прогнозов или насколько можно доверять собранным статистическим данным. Школьной математики для этого точно будет недостаточно.
При программировании нейросетей иногда даже знаний дата-сайентиста будет недостаточно. Например, для распознавания точных форм объекта на фотографии нужно уметь работать с кривыми, заданными различными формулами, считать пространственные координаты и определять глубину объекта. Всё это — отдельные области математики, без которых не получится собрать нужную нейросеть.
Где подтянуть математику:
Примеры и задачи из жизни аналитиков
Антон Леонов, аналитик в X5 Retail Group
Часть наших задач можно описать так: есть какой-то отчёт, нам нужно сделать так, чтобы он формировался автоматически и с нужными данными. Вот пара примеров:
👉 В разных магазинах могут различаться ходовые и неходовые товары. Например, в одном магазине любят печенье «Юбилейное», а в другом его почти не берут. Мы хотим понимать по каждому конкретному магазину, сколько закупили, сколько продали, сколько списали каждой позиции. Затем мы смотрим, какие товары двигаются хуже, и даём сигнал людям на местах, например, устроить промо определённых товаров в тех магазинах, где с ними есть проблемы.
👉 Сейчас мы автоматизируем отчётность, которая идёт руководителям сетей. Раньше коллеги руками собирали эксель-файл, затем руками переносили данные на слайды — не очень надёжный подход. Мы делаем систему, которая сама ходит за данными, а потом их визуализирует, руками делать ничего не нужно, ошибок меньше.
Бывает так, что данные есть в какой-то устаревшей системе. Тогда нужно провести реверс-инжиниринг, разобраться, как она работает. Или не хватает бизнес-требований, тогда мы их пишем самостоятельно.
Анастасия Никулина, дата-сайентист Росбанка
В 2019 году мне предложили работать в рекламном агентстве OMD OM Group — так я выросла до мидла и решила полностью погрузиться в дата-сайенс.
В агентстве мы анализировали соцсети, собирали пользовательские данные и помогали маркетологам создавать эффективную рекламу — мы делали так, чтобы объявления доходили до целевой аудитории. Чтобы мужчины не получали предложений о женской косметике, а девушки — препараты от облысения (это шутка: реклама бывает разной и зависит от многих факторов).
Интервью с Анастасией Никулиной
Тагир Хайрутдинов, главный аналитик в «Альфа-Банке»
Кто такой аналитик? Это человек, который на основании данных может помочь бизнесу ответить на вопросы. На основании этих цифр бизнес будет принимать решения, важные для себя. Круто ощущать себя тем человеком, который подходит к какой-то задаче с разных сторон. Смотрит, считает какие-то метрики, думает в целом, как работает продукт. И этим можно даже влиять на продукт с какой-то стороны.
У аналитиков очень нетривиальные задачи. Если ты разработчик, ты пишешь код, ты занимаешься разработкой. А если ты аналитик, например в «Озоне», то в один день к тебе придёт продакт и скажет: «Слушай, у нас есть гипотеза, что при поиске приложение показывает в феврале в поисковой выдаче по запросу „куртка“ один и тот же товар человеку, который живёт в Сочи, и человеку, который живёт в Сибири. Логично бы сибиряку показывать пуховик на минус 30, а чуваку из Сочи показывать ветровку или весеннюю куртку. Звучит очевидно, но нужно проверить цифрами, сможешь?».
И ты сидишь, и ты думаешь, пытаешься проанализировать, как можно подойти к этой задаче, как можно посчитать, как можно на основании цифр показать, что это действительно так. А может, это окажется не так — и это тоже результат.
Интервью с Тагиром Хайрутдиновым
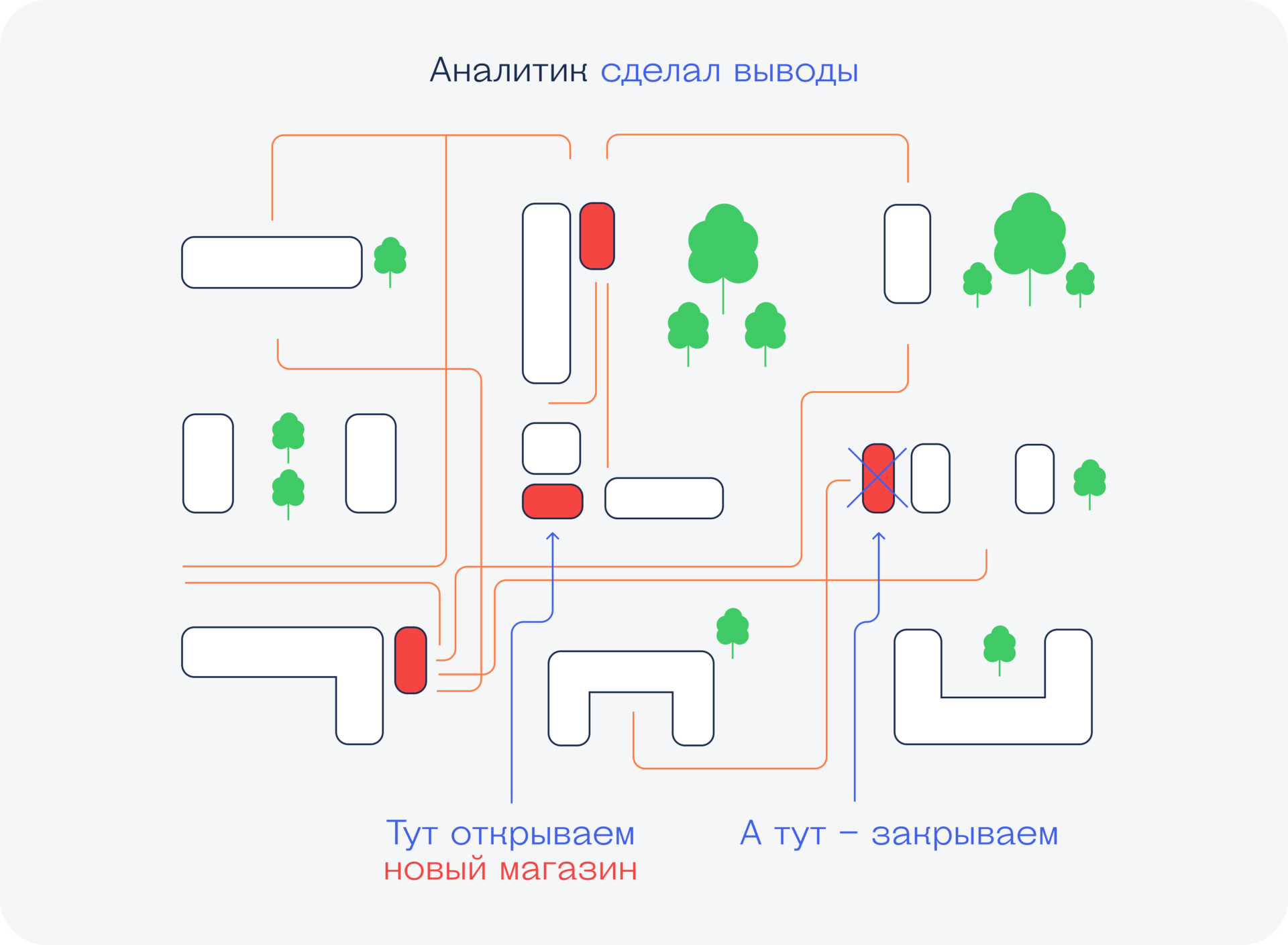
Фантазийный пример: Data Science и аналитика для принятия решения об открытии магазина
Возьмём пример, где данные, аналитика и модели предсказаний могут стоить компании миллионы, а экономить (или зарабатывать) сотни миллионов.
Иногда, стоя на перекрёстке, можно увидеть вокруг несколько магазинов одной и той же сети: «Пятёрочки», «Дикси» или любые другие. Некоторые думают, что в этом нет никакого смысла: зачем строить новый магазин, когда через дорогу есть точно такой же?
Вот как к этому вопросу могли бы подойти магазины, работай они с данными профессионально. Сейчас будет упрощённая модель, но по сути верная.
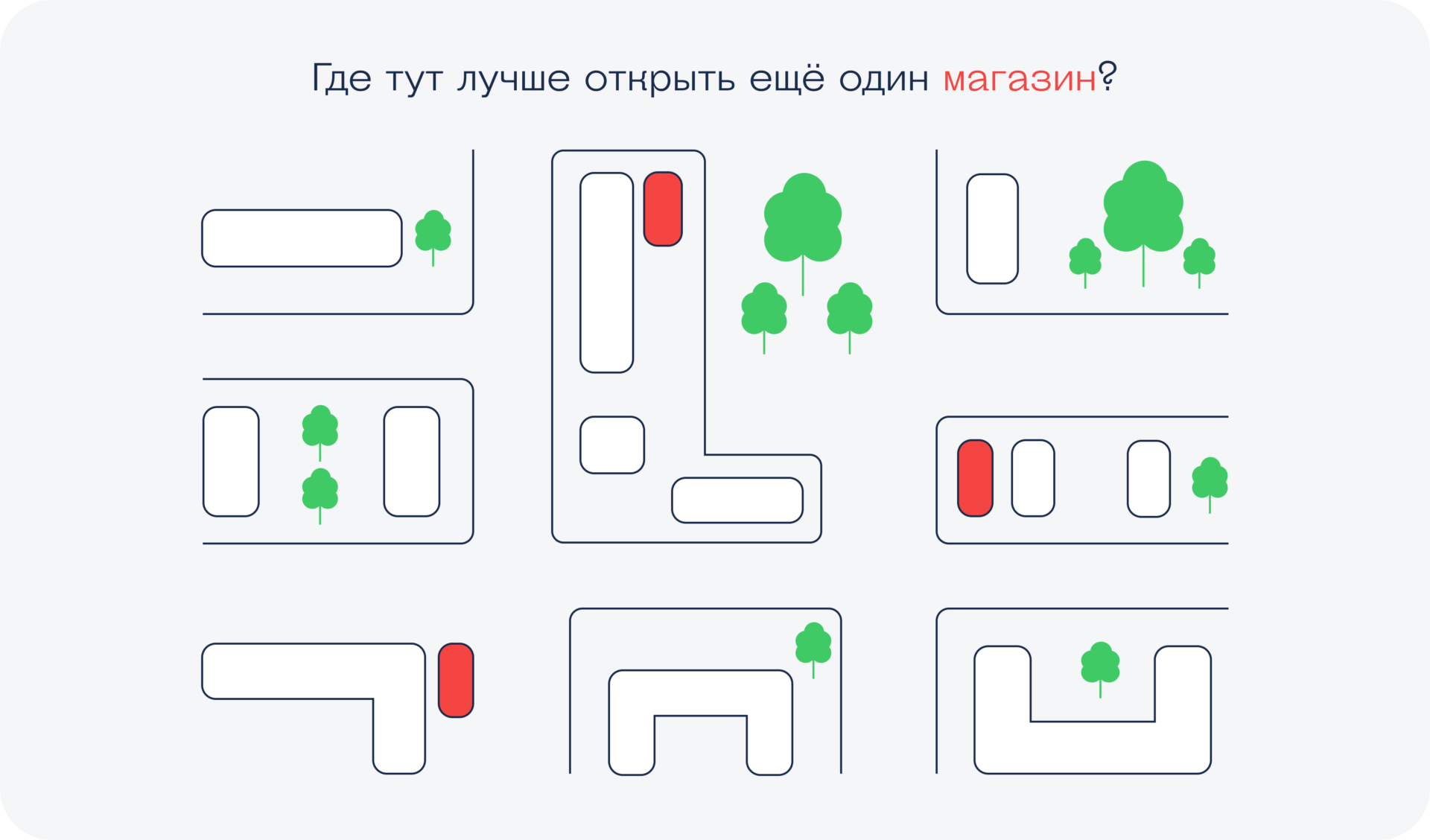
Магазин типа «Пятёрочки» надо открывать там, где ходят люди. Никто специально не поедет в соседний район ради продуктового магазина, поэтому для начала нужно ответить на такие вопросы:
- Где в этом районе ходят люди?
- По каким маршрутам?
- Сколько их в разное время?
- А где точно не ходят?
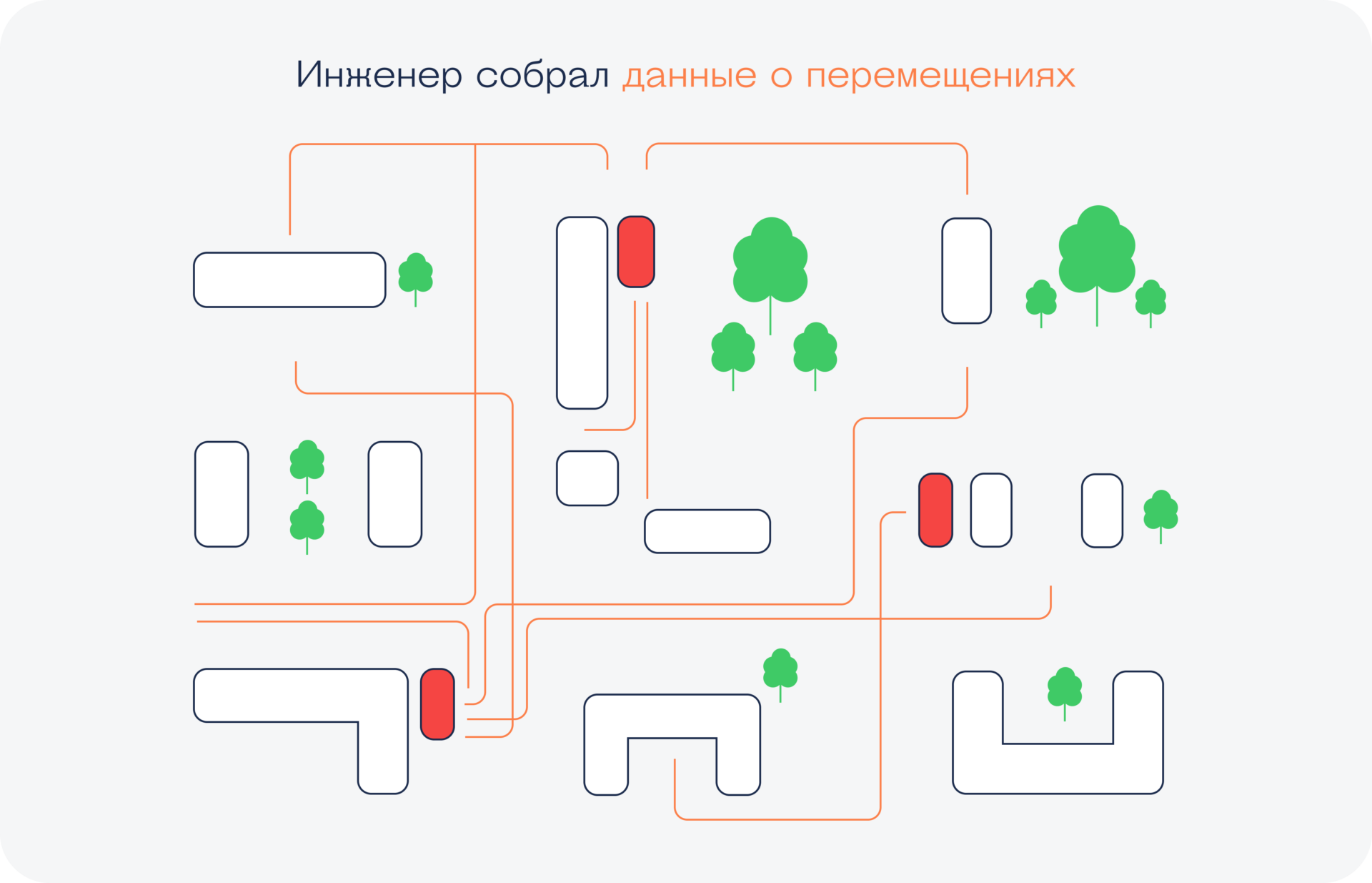
Чтобы это узнать, можно воспользоваться бигдатой: собрать её или заполучить. Для этого зовут инженера по сбору данных, который находит оптимальный способ найти нужную информацию, например:
- У сотового оператора.
- Поставить Wi-Fi- и Bluetooth-точки в разных местах нужного района.
- Поставить камеры с распознаванием лиц.
Всё это может придумать и в какой-то степени реализовать дата-инженер.
После того как мы получили карту перемещений, её нужно проанализировать и найти те точки, где проходит максимальное количество пешеходов. В идеале — найти такие места, где пешеходный поток не заходит в магазины конкурентов или где их вообще нет. Это уже задача аналитика данных.
Открываем магазины в нужных местах (поможет аналитик данных)
Задача розничной сети — получить как можно больше прибыли с каждого района в городе. Это значит — открыть столько магазинов, сколько это физически возможно и прибыльно.
Допустим, мы уже открыли много магазинов в каждом районе города. Задача аналитика — спуститься с уровня города на уровень жилого квартала. Кажется, что если один магазин уже стоит во дворе, то на соседней улице нет смысла открывать такой же — достаточно перейти через дорогу. Но это не всегда так.
Через некоторое время после открытия первого магазина мы снова начинаем смотреть на пешеходные потоки — как они изменились. Иногда мы предполагаем, что люди будут переходит через дорогу, чтобы зайти в наш магазин, но на деле это часто не так. Обычно бывает, что магазин притягивает одну часть пешеходов, а другая ходит сама по себе. Можно ли эту часть переманить?
На этом этапе мы ставим перед аналитиком такую задачу — найти место на другой стороне улицы, где больше всего проходит тех людей, кто не заходит в наш первый магазин. Снова собираем много данных, анализируем их и находим нужное место.
Иногда может так получиться, что с одного перекрёстка видно сразу несколько таких одинаковых магазинов. Это значит, что в этом районе есть несколько независимых основных пешеходных маршрутов. И те, кто ходит в «Пятёрочку» за углом, обычно не ходят в «Пятёрочку» у светофора — это дольше и совсем не по пути.
Вопросы и ответы
Что лучше выбрать — Data Science или Machine Learning?
На старте лучше заняться Data Science — это проще, меньше математики, и первые ощутимые результаты там можно получить гораздо быстрее.
Сколько времени реально надо, чтобы освоить минимум и попробовать себя в профессии
Если реально — то месяца 3–4 плотной работы и изучения нового. Причём нужный минимум можно освоить за 2–3 недели, а остальное время уйдёт на практику и проверку усвоенных знаний. Одно дело, когда ты что-то знаешь в теории, и другое — когда можешь сам запустить это у себя на компьютере.
Ещё вариант — снизить нагрузку и заниматься фоново, пару часов в день после работы или учёбы. В этом случае полугода будет достаточно, чтобы попробовать себя в деле и понять, хотите ли вы этим заниматься дальше на профессиональном уровне или нет.
Какая техника нужна для работы с бигдатой
На самом деле заниматься машинным обучением можно почти на любом компьютере — другое дело, насколько быстро будет там работать нейросеть.
Вся работа в дата-сайенсе делится на две части: написание кода и работа нейросети — обучение, калибровка, запуск и отладка. Для написания кода достаточно любого текстового редактора, а для всего остального действует такое правило: чем мощнее, тем лучше.
Если есть возможность, лучше заниматься бигдатой на компьютерах с видеокартами Nvidia — у них есть поддержка технологии CUDA, которая здорово ускоряет все вычисления. Ещё видеокарта сама по себе позволяет быстро вычислять простейшие операции с матрицами — в этом ей помогают большое количество ядер и скоростная память.
Ещё вариант — использовать мощности Google Colab, специального сервиса для облачной работы с машинным обучением и бигдатой. На бесплатных версиях есть свои ограничения, но, когда вы с ними столкнётесь, к этому времени вы уже будете сильно в теме.
Можно ли перейти в бигдату из обычного программирования
Да, если подтянуть математику и алгоритмы нейросетей. Тем, кто уже знает программирование, будет намного проще заняться бигдатой, чем стартовать с нуля. Многие программисты из тех, что сейчас занимаются искусственным интеллектом, начинали как обычные Python-разработчики.
Куда идти учиться
Самый простой способ ворваться в бигдату — прийти в Практикум на курсы. Учиться можно двумя способами:
Обучение в обычном темпе длится от 6 до 9 месяцев, на буткемпе — в 2–3 раза быстрее. На выходе у вас портфолио с учебными проектами, навыки для работы в отрасли и помощь карьерного центра.
Если нужны конкретные курсы — держите:
Если интересно, как вообще устроены такие курсы, почитайте наш разбор обучения в Практикуме. Там всё как раз на примере курсов про бигдату.
Что дальше
Работа с большими данными — это перспективное направление, которое будет актуально ещё много лет. Всё дело в том, что данных становится всё больше и с ними нужно как-то уметь работать. На основе выводов из данных компании принимают решения, которые помогут развиваться их бизнесу, поэтому хорошие специалисты по работе с данными сейчас в цене.
Если вы ещё не решили, что выбрать в бигдате, — попробуйте себя в каждой роли:
- соберите бигдату на основе разных источников;
- проанализируйте её и попробуйте сделать выводы;
- постройте простую нейросеть, которая сможет предсказывать результаты при разных входных параметрах.
Что из этого понравится больше всего — на том и остановитесь для начала. А как разберётесь поглубже, сможете сами принять верное для себя решение.








