








Когда мы говорим, что нейросеть «учится», то немного лукавим. На самом деле она просто решает огромную математическую задачу по поиску минимальной ошибки. Изначально модель ничего не знает и выдает случайные ответы. Чтобы стать умнее, ей нужен механизм, который подскажет, в какую сторону нужно поменять свои внутренние настройки, чтобы в следующий раз ошибиться чуть меньше.
Этот механизм — градиентный спуск, главный двигатель современного машинного обучения. Именно он шаг за шагом ведет модель к правильным ответам. То, насколько сильно предсказания модели расходятся с реальностью, измеряет функция потерь в ML. А градиентный спуск — это способ сделать значение этой функции как можно ближе к нулю.
Сегодня разберемся в механизме градиентного спуска и напишем свой собственный алгоритм оптимизации на Python.
Что такое градиентный спуск и зачем он нужен
В машинном обучении невозможно просто угадать идеальные параметры сети. Нам нужен методичный способ их поиска среди миллионов возможных вариантов. Таким способом является математическая оптимизация.
Функция потерь и задача оптимизации
Каждый раз, когда модель делает предсказание, алгоритм сравнивает этот ответ с реальностью и выдает число — размер ошибки. Чтобы понимать, почему такие оценки работают, полезно держать в голове теорию вероятности в машинном обучении. Если модель работает плохо, число получается большим. Функция потерь в ML показывает этот масштаб ошибок. Задача оптимизации состоит в том, чтобы найти такие значения весов, при которых значение функции потерь будет наименьшим. То есть мы ищем самую низкую точку на графике возможных ошибок.

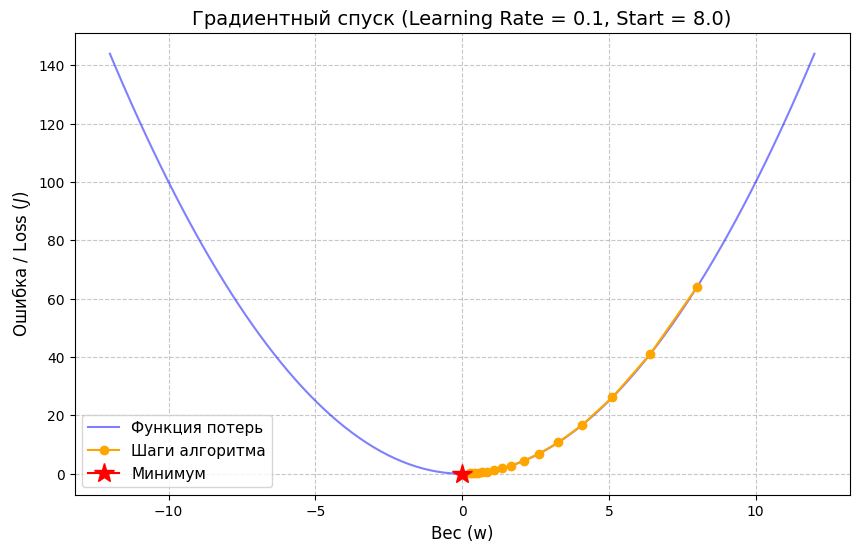
Интуиция алгоритма
Чтобы понять алгоритм, представьте человека на склоне горы в густом тумане. Его цель — спуститься в самую низкую точку долины. Он не видит всю картину целиком, но может нащупать ногой уклон рельефа под собой. Градиент — это вектор, который вычисляется через обратное распространение ошибки и всегда указывает в сторону самого крутого подъема. Чтобы спуститься в долину, алгоритм берет текущие координаты, определяет градиент и делает небольшой шаг в строго противоположную сторону — по антиградиенту.
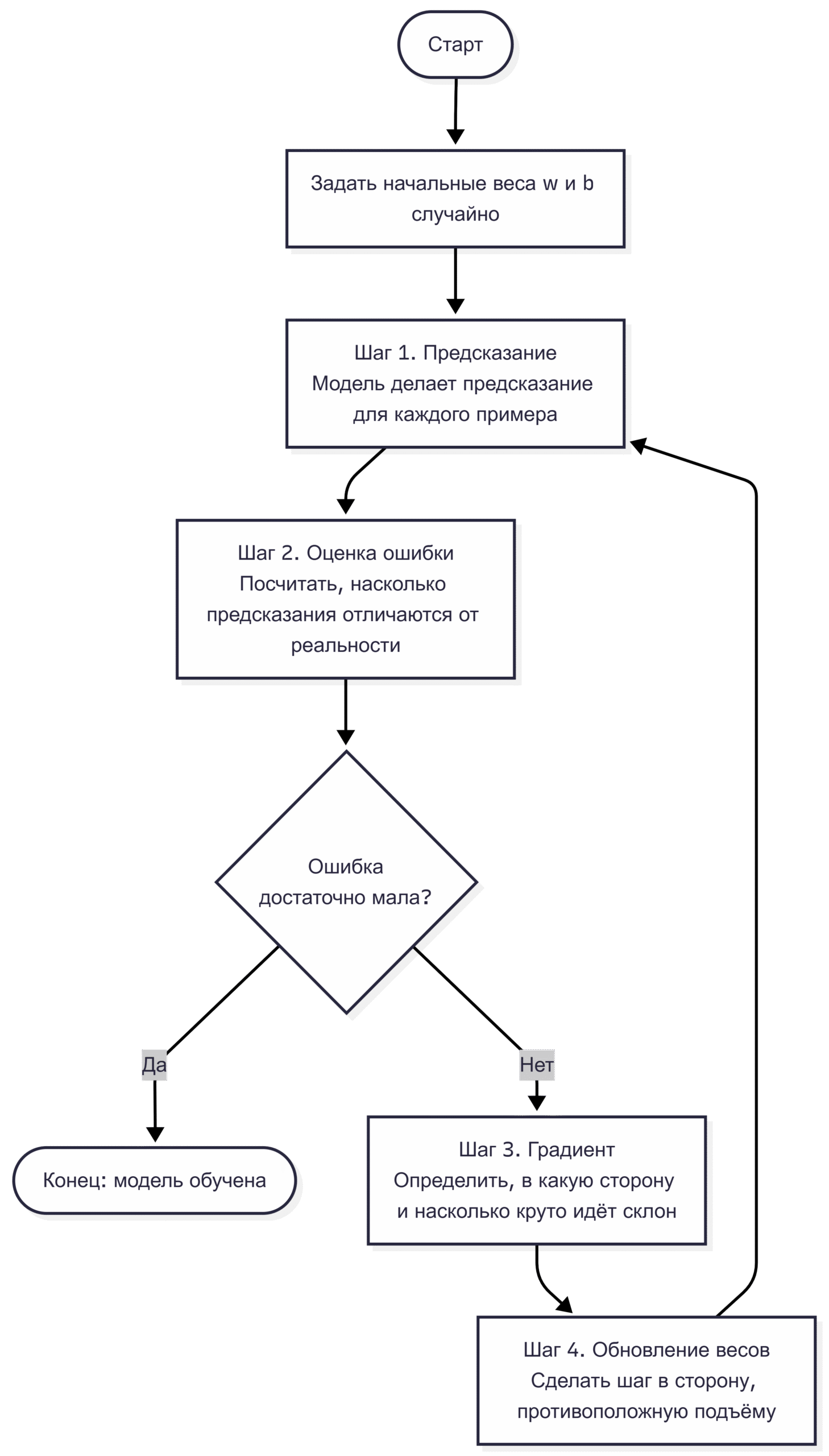
Разберем процесс по шагам:
Шаг 1. Как модель делает предсказание
У модели есть параметры — веса, которые она должна настроить. Допустим, мы предсказываем цену квартиры y по её площади x. Базовая формула предсказания выглядит как уравнение прямой:

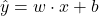
x — входные данные (площадь).
w — вес признака: насколько сильно x влияет на цену.
b — смещение: базовая стоимость.
ŷ— то, что предсказала модель.
Наша задача — найти такие идеальные w и b, при которых ŷ будет максимально близко к реальной цене y.
Шаг 2. Как мы оцениваем ошибку
Чтобы понять, насколько мы ошиблись, нужна функция потерь (Loss Function), обозначаемая J. Самая популярная для задач регрессии — MSE (Mean Squared Error, среднеквадратичная ошибка):

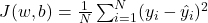
N — количество примеров в датасете.
yi— реальная цена i-й квартиры.
ŷi— предсказанная цена i-й квартиры.
(…)2 — возведение в квадрат избавляет от отрицательных значений и сильнее штрафует модель за крупные промахи.
Эта функция рисует ту самую «гору» в пространстве параметров — параболу, на дно которой нам нужно спуститься. Чем меньше J, тем точнее модель.
Шаг 3. Куда шагать — градиент
Градиент — это вектор из частных производных функции потерь по каждому из параметров. Производная показывает крутизну склона в текущей точке. Если взять производную J по весу w, получится:

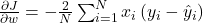
Это выражение делает простую вещь: считает, как сильно изменение w повлияет на итоговую ошибку. Если

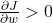
— склон идёт вверх,
если
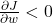
— вниз.
Шаг 4. Делаем шаг — правило обновления весов
Вычислив градиент, алгоритм корректирует текущие веса так, чтобы на следующей итерации ошибка стала чуть меньше:

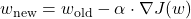
Wold— текущий вес (наша точка на горе).
∇J(w)— градиент, указывающий в сторону самого крутого подъёма.
Знак – означает, что мы идём в противоположном направлении — то есть спускаемся.
α — скорость обучения (Learning Rate): гиперпараметр, определяющий длину шага.
Подробнее мы поговорим о скорости обучения позже, а пока запомним: при слишком малом α алгоритм будет сходиться бесконечно долго; при слишком большом α — «перепрыгивать» через минимум J, не в состоянии на нём остановиться.
Повторяя эти четыре шага снова и снова, алгоритм постепенно движется к минимуму J — туда, где модель ошибается меньше всего.

Полезный блок со скидкой
Градиентный спуск — это фундамент. Следующий шаг — научиться строить на нём реальные модели, понимать архитектуры и развиваться в сторону ML-инженера и зарабатывать больше, — держите промокод Практикума на любой платный курс: KOD (можно просто нажать). Он даст скидку при покупке и позволит сэкономить на обучении.
Бесплатные курсы в Практикуме тоже есть — по всем специальностям и направлениям, начать можно в любой момент, карту привязывать не нужно, если что.
Три варианта градиентного спуска
В зависимости от объема данных алгоритм может использовать разные стратегии для расчета уклона. От этого зависит скорость и плавность обучения.
Batch Gradient Descent
В этом варианте алгоритм берет весь обучающий датасет, пропускает его через модель, вычисляет среднюю ошибку и только после этого делает один точный шаг. Это дает идеальное направление к минимуму. Однако, если у нас миллионы изображений, расчет всего одного такого шага потребует колоссальных затрат времени и оперативной памяти.
Формула:

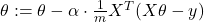
Где:
θ — веса модели,
α — скорость обучения (learning rate),
m — количество примеров в датасете,
X — матрица признаков,
y — вектор истинных ответов.
Stochastic Gradient Descent
Стохастический подход решает проблему долгих вычислений радикально: он берет всего один случайный пример из данных, считает градиент только по нему и сразу обновляет веса. Вычисления происходят мгновенно, но вектор направления становится очень хаотичным, и алгоритм спускается в долину резкими зигзагами. Если интересно углубиться в математику процесса, рекомендуем изучить теоретическое обоснование сходимости SGD в открытых курсах.
Mini-batch Gradient Descent
Золотая середина. Весь набор данных разбивается на небольшие пакеты — обычно по 32, 64 или 128 примеров. Этот подход сочетает высокую скорость вычислений SGD и стабильность классического метода. Видеокарты отлично оптимизированы под матричные вычисления таких размеров. Кроме того, легкий шум от мини-батчей помогает модели не зазубривать данные и снижает риск переобучения нейросети.

Каждый вариант легко реализуется на Python, понадобится только numpy.
Batch Gradient Descent:
def batch_gradient_descent(X, y, theta, alpha, iterations):
m = len(y)
for i in range(iterations):
# 1. Вычисляем предсказания для всего датасета
predictions = X.dot(theta)
# 2. Находим разницу между предсказаниями и реальными значениями
error = predictions - y
# 3. Вычисляем средний градиент по всем примерам
gradient = (1/m) * X.T.dot(error)
# 4. Обновляем веса
theta = theta - alpha * gradient
return thetaStochastic Gradient Descent:
def stochastic_gradient_descent(X, y, theta, alpha, iterations):
m = len(y)
for i in range(iterations):
# Выбираем индекс одного случайного примера
random_index = np.random.randint(m)
xi = X[random_index:random_index+1]
yi = y[random_index:random_index+1]
# Считаем ошибку и градиент только для этого примера
prediction = xi.dot(theta)
error = prediction - yi
gradient = xi.T.dot(error)
# Сразу обновляем веса
theta = theta - alpha * gradient
return thetaMini-batch Gradient Descent:
def mini_batch_gradient_descent(X, y, theta, alpha, epochs, batch_size):
m = len(y)
for epoch in range(epochs):
# Перемешиваем индексы датасета перед каждой эпохой
indices = np.random.permutation(m)
X_shuffled = X[indices]
y_shuffled = y[indices]
# Нарезаем перемешанный массив на батчи (через срезы)
for i in range(0, m, batch_size):
xi = X_shuffled[i:i+batch_size]
yi = y_shuffled[i:i+batch_size]
# Обновляем веса для текущего мини-батча
predictions = xi.dot(theta)
error = predictions - yi
gradient = (1/len(xi)) * xi.T.dot(error)
theta = theta - alpha * gradient
return thetaLearning Rate — ключевой гиперпараметр
Learning rate, или скорость обучения (обычно обозначается буквой α или ƞ), — это множитель, который определяет, насколько большим будет шаг алгоритма в сторону минимума.

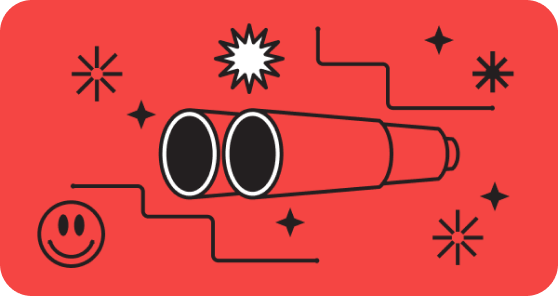
Эффекты слишком большого и слишком малого α
Если α слишком мал, алгоритм будет двигаться микроскопическими шагами, и обучение займет неприемлемо много времени. Если α слишком велик, алгоритм перешагнет сам минимум, оттолкнется от противоположной стены функции и «улетит» в бесконечность — модель разойдется и не сможет ничему научиться.

Learning Rate Scheduling
Вместо того чтобы искать одно идеальное значение на весь процесс обучения, на практике используют динамические подходы. В начале тренировки шаг делают большим, чтобы быстро спуститься с крутых склонов. По мере приближения к минимуму размер шага постепенно уменьшают, чтобы алгоритм мог аккуратно нащупать самое дно и не перескочить его.
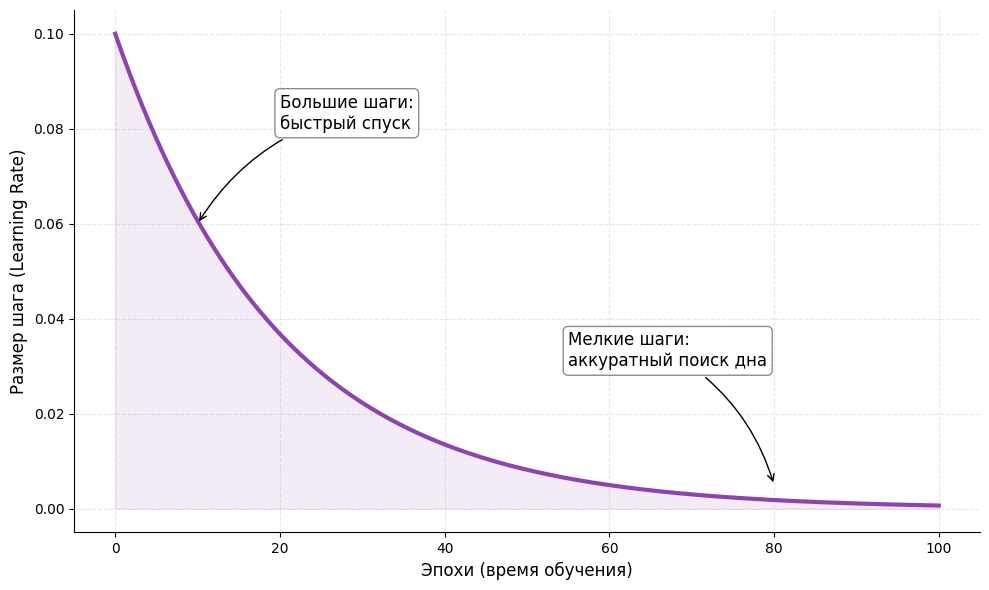
Чтобы алгоритм быстро двигался к цели в начале, но не «перепрыгивал» через минимум в конце, скорость обучения можно менять прямо в процессе работы. Существуют три основные стратегии:
- Константный LR: скорость обучения остается неизменной на протяжении всего процесса (просто, но не всегда эффективно).
- Step decay (ступенчатое затухание): LR искусственно уменьшается в определенное количество раз каждые N пройденных эпох.
- Cosine annealing (косинусное затухание): LR плавно убывает по кривой косинуса, постепенно снижаясь к нулю к концу обучения.
Проблемы сходимости и как их решать
В теории алгоритм выглядит безотказным, но на практике многомерные пространства глубокого обучения готовят оптимизатору немало препятствий. Самые частые — сёдловые точки и перемножение ошибочных значений из предыдущих слоёв.
Локальные минимумы и сёдловые точки
Раньше считалось, что главная проблема — это локальные минимумы (ямки на склоне горы, которые алгоритм может принять за глобальное дно). Но в сетях с миллионами параметров шанс застрять в локальной яме математически мал. Реальный враг — сёдловые точки. Это места, где функция имеет минимум по одной оси и максимум по другой. Градиент там равен нулю, и алгоритм может надолго застрять на абсолютно ровном плато, перестав обучаться.

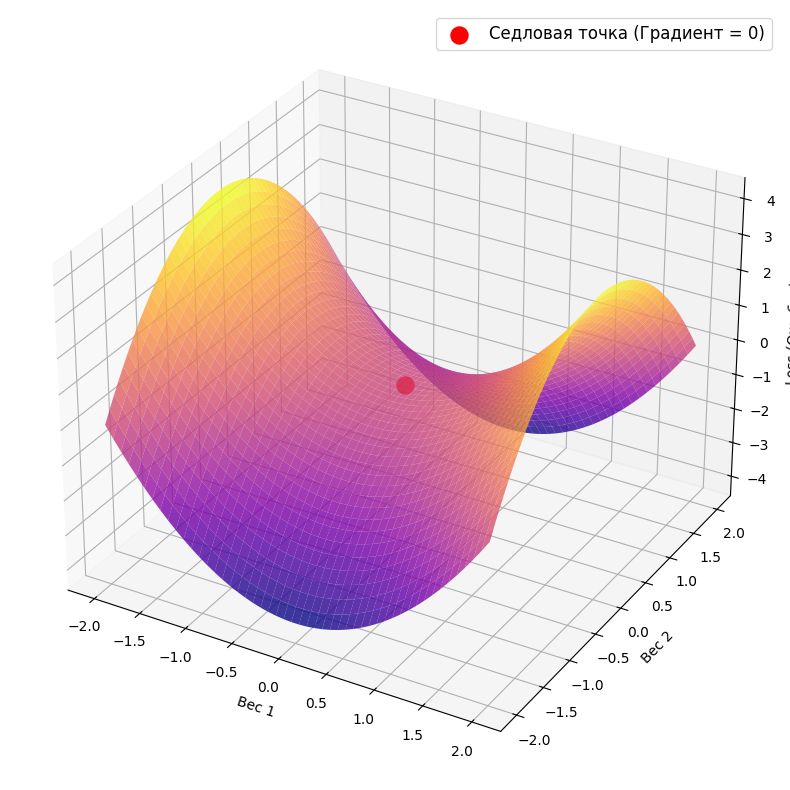
Приглядитесь к рельефу — в сёдловой точке он ведет себя коварно:
- Если посмотреть вдоль оси X (Вес 1), поверхность образует U-образную впадину-параболу. То есть, если двигаться только по этому направлению, наша красная точка — это минимум.
- Но если посмотреть вдоль оси Y (Вес 2), поверхность образует перевернутую параболу. По этому направлению красная точка — это максимум.
В чем проблема для алгоритма? В красной точке поверхность абсолютно плоская — уклон равен нулю. Когда базовый градиентный спуск попадает сюда, он «оглядывается», видит, что явного склона под ногами нет, и ошибочно решает, что долина найдена и спуск окончен. Алгоритм застревает на месте, хотя на самом деле ему нужно просто сделать шаг вбок по оси Y, чтобы продолжить катиться вниз к настоящему минимуму.
Исчезающий и взрывной градиент
Когда ошибка передается от последних слоев нейросети к самым первым, её значения последовательно перемножаются. Если числа меньше единицы, градиент быстро становится неотличимым от нуля и сеть перестает учиться. Если больше единицы — числа быстро растут до огромных и вычисления ломаются. Для решения этих проблем применяют специальные функции активации и нормализацию батчей.
Функции активации — это математические фильтры, которые решают, передавать сигнал дальше по сети или нет. Чаще всего используют функцию ReLU (Rectified Linear Unit). Она все отрицательные числа превращает в ноль, а положительные пропускает без изменений. Это позволяет градиенту проходить сквозь десятки слоев сети, не теряя своей силы.
Нормализация батчей принудительно выравнивает масштаб данных перед каждым слоем. Представьте, что на каждом слое нейросети масштаб чисел начинает скакать: на одном слое числа от -1 до 1, а на следующем — от -1000 до 1000. Из-за этого градиенту очень сложно найти правильное направление. Нормализация собирает мини-батч, находит в нём среднее значение и делает так, чтобы данные распределялись вокруг нуля. Это делает рельеф функции потерь более гладким, убирает резкие скачки и позволяет смело использовать большой Learning Rate.


Оптимизаторы: расширения базового SGD
Базовый спуск работает хорошо, но ученые придумали элегантные способы сделать его быстрее и умнее, добавив в формулы учет истории прошлых шагов.
Momentum
Momentum переводится как инерция. Алгоритм с инерцией ведет себя как тяжелый шар, который катится с горы. Если он долго катится в одном направлении, он набирает скорость. Это помогает ему сглаживать хаотичные зигзаги и на скорости проскакивать плоские участки и сёдловые точки, где обычный алгоритм бы остановился.

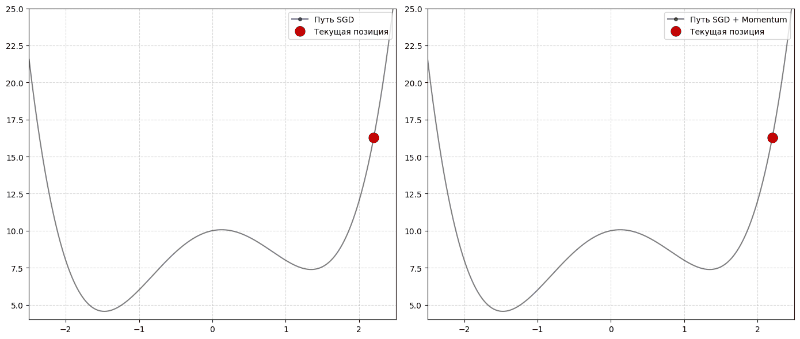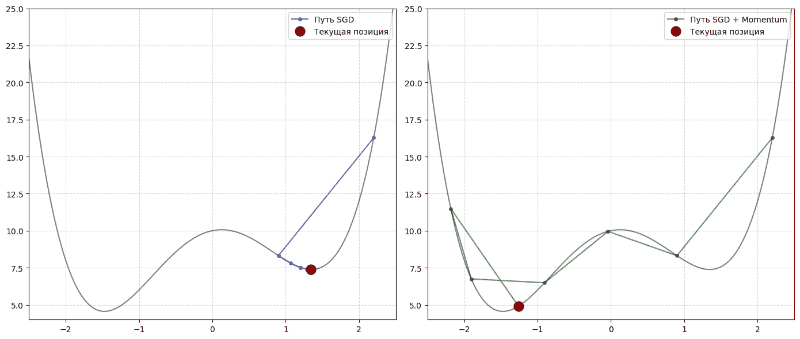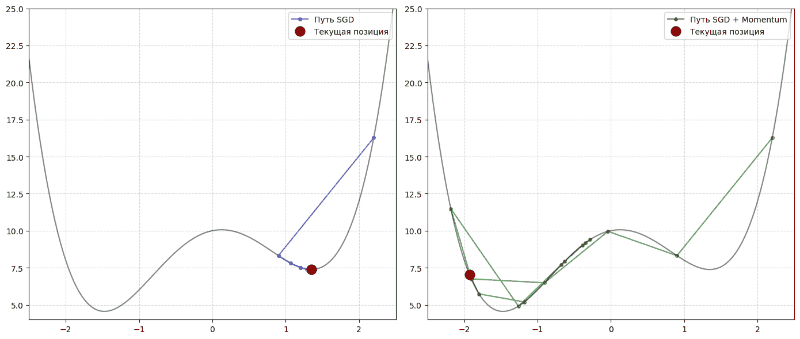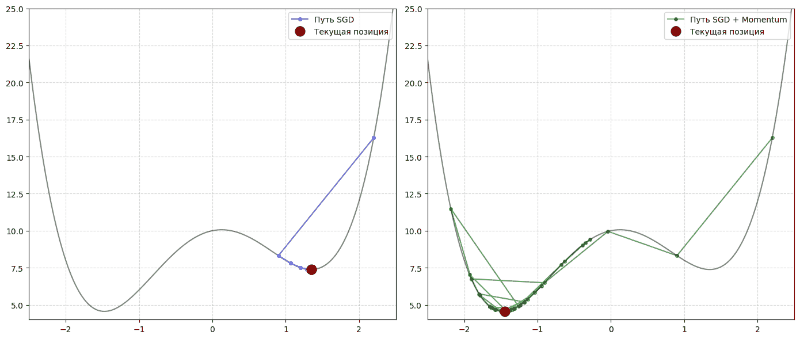
Формула:

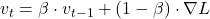

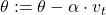
Инерция помогает градиентному спуску накапливать скорость в том направлении, где градиент ∇L стабилен, и гасить колебания там, где градиент постоянно меняет знак.
В формуле vₜ — это экспоненциальное скользящее среднее прошлых градиентов, а параметр β (обычно 0,9) определяет, насколько сильно мы учитываем прошлые шаги.
RMSprop
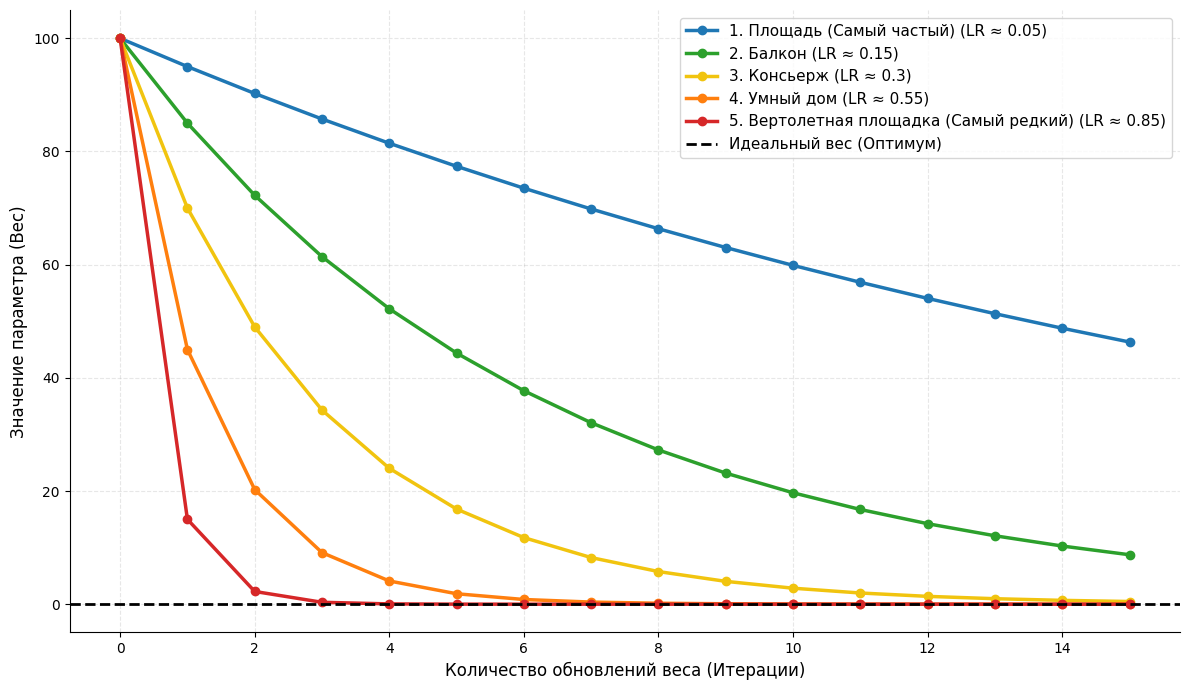
В сложных задачах некоторые параметры встречаются часто, а некоторые — крайне редко. Метод RMSprop анализирует историю градиентов и делает большие шаги для редких признаков, а для частых — аккуратные и маленькие. Скорость обучения становится адаптивной и рассчитывается для каждого веса отдельно.
Давайте разберем эту логику на классической задаче: мы обучаем модель предсказывать стоимость недвижимости. В наших данных есть множество параметров, которые влияют на итоговый ценник.
Допустим, у нас есть пять признаков разной степени редкости:
- Площадь. Этот параметр есть у абсолютно каждой квартиры в базе. Модель натыкается на него постоянно, и градиент для этого веса обновляется на каждом шаге. Если оптимизатор будет делать большие шаги, модель начнет «штормить», и она проскочит идеальный вес. Поэтому RMSprop автоматически «тормозит» обучение для этого признака, делая шаги очень мелкими и аккуратными.
- Наличие балкона. Встречается часто, но не везде. Шаг чуть больше.
- Наличие консьержа. Встречается в каждой пятой новостройке. Средний шаг.
- Умный дом. Редкая фича, есть в премиум-сегменте. Шаг большой.
- Вертолетная площадка на крыше. Встречается в одной из тысячи записей. Если модель будет менять вес этого признака такими же микро-шажками, как у «площади», она никогда не научится адекватно оценивать влияние вертолетной площадки на цену. Поэтому RMSprop видит, что этот параметр обновляется крайне редко, и выдает ему огромный размер шага, чтобы модель усвоила информацию с первого же раза.

Формула:

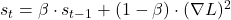

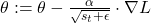
Мы накапливаем квадрат градиента sₜ (чтобы понимать масштабы изменений). При обновлении весов мы делим градиент на корень из этого накопленного значения √(sₜ + ∈) (где ∈ — маленькое число, чтобы избежать деления на ноль). Таким образом, параметры, которые редко обновлялись, получают больший шаг, а те, что скачут слишком сильно — сдерживаются. Это решает проблему затухающих и взрывающихся градиентов.
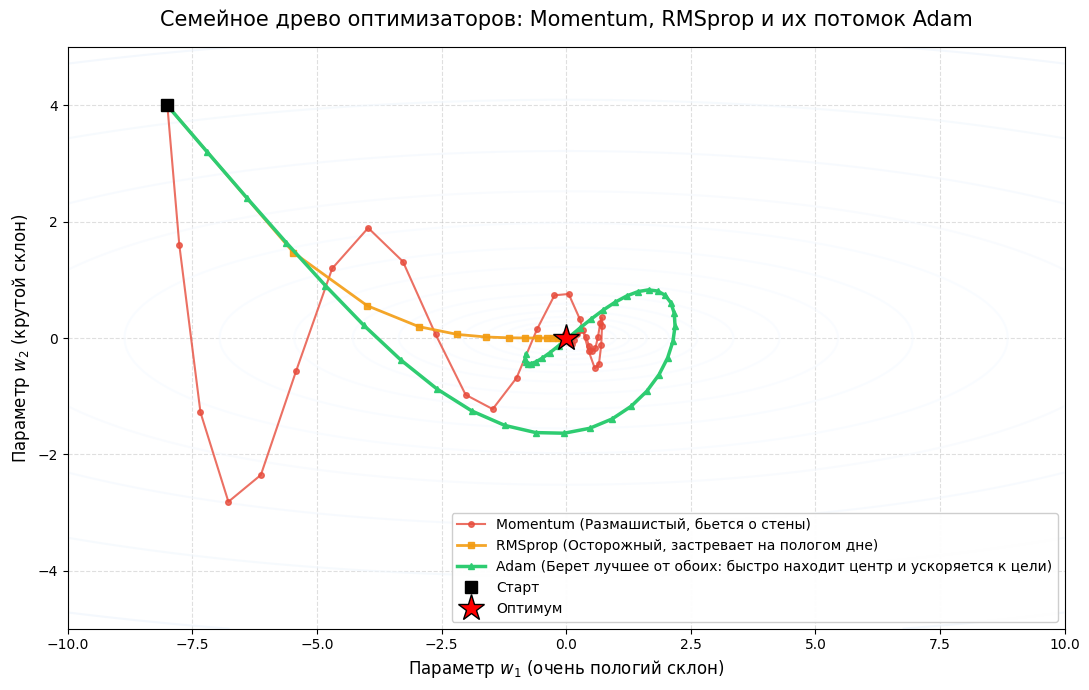
Adam (Adaptive Moment Estimation)
Adam — лучший на сегодня оптимизатор градиентного спуска в глубоком обучении. Своей популярностью он обязан тому, что не изобретает колесо, а берет лучшие и уже проверенные черты двух своих предшественников: инерцию от Momentum и адаптивность от RMSprop.
- Накопление скорости. Adam вычисляет первый момент — экспоненциально скользящее среднее прошлых градиентов. Благодаря этому алгоритм помнит, куда он двигался на предыдущих шагах. Если он попадает на ровное плато или в небольшую ямку, инерция помогает ему проскочить сложные участки и не топтаться на месте.
- Индивидуальный размер шага. Adam вычисляет второй момент — скользящее среднее квадратов прошлых градиентов. Алгоритм анализирует каждый параметр отдельно: если по какой-то оси склон слишком крутой, он тормозит шаг, а если пологий — ускоряет.
Если просто сложить два этих метода, в самом начале обучения алгоритм будет работать плохо. Поскольку истории шагов еще нет (переменные стартуют с нулей), метод будет делать микроскопические, неуверенные шаги. Чтобы этого избежать, Adam использует математический трюк — коррекцию смещения. Она искусственно «разгоняет» алгоритм на первых итерациях, пока он не накопит достаточно статистики.
В результате получается невероятно быстрый и стабильный алгоритм, который отлично работает «из коробки» и прощает неидеальный выбор начального learning rate. За детальным математическим обоснованием можно обратиться к оригинальной статье по Adam от его создателей.

Сравнение оптимизаторов:
| Оптимизатор | Скорость сходимости | Точность поиска минимума | Когда применяют | Распространенность на практике |
| SGD | Низкая | Высокая (при хорошей настройке LR) | Простые линейные модели, базовая аналитика. | Средняя (в чистом виде используется редко). |
| SGD + Momentum | Средняя | Высокая | Компьютерное зрение, например, если Adam переобучается. | Высокая |
| RMSprop | Высокая | Средняя/Высокая | Рекуррентные нейросети, задачи NLP. | Средняя. |
| Adam | Очень высокая | Высокая | Сложные многослойные нейросети по умолчанию. | Повсеместная |
Реализация с нуля на Python
Вместо использования готовых библиотек напишем чистую математическую реализацию градиентного спуска с помощью NumPy. В реальных проектах для этого обычно используют готовые библиотеки машинного обучения для Python.
import numpy as np
# Генерируем случайные данные для простой регрессии
np.random.seed(42)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
# Добавляем единичный столбец для свободного члена (bias)
X_b = np.c_[np.ones((100, 1)), X]
def train_gradient_descent(lr, iterations=50):
# Случайная инициализация весов модели
theta = np.random.randn(2, 1)
m = len(X_b)
loss_history = []
for iteration in range(iterations):
# 1. Вычисляем градиент по всем данным
gradients = 2/m * X_b.T.dot(X_b.dot(theta) - y)
# 2. Делаем шаг в сторону антиградиента
theta = theta - lr * gradients
# 3. Считаем текущую ошибку (MSE) для мониторинга
loss = np.mean((X_b.dot(theta) - y)**2)
loss_history.append(loss)
return theta, loss_history
# Обучаем модель
final_weights, history = train_gradient_descent(lr=0.1)
print("Найденные веса:", final_weights.ravel())Вывод консоли:
Найденные веса: [3.91125197 3.03839129]Вы не спрашивали, но мы ответим
Всегда ли алгоритм находит глобальный минимум?
Нет. Для простых моделей с выпуклыми функциями потерь, например, логистическая регрессия, — да, он всегда найдет идеальную точку. Но для глубоких нейросетей ландшафт настолько сложен, что алгоритм находит достаточно хороший локальный минимум, которого хватает для отличной работы модели.
Чем эпоха отличается от итерации?
Эпоха — это когда алгоритм просмотрел абсолютно весь доступный тренировочный датасет. Итерация — это один шаг обновления весов. При BGD эпоха равна одной итерации, а при Mini-batch одна эпоха может состоять из сотен итераций.
Заключение
Магия машинного обучения основана на понятной и строгой математике. За умением нейросетей распознавать лица, генерировать тексты и предсказывать погоду стоит методичный поиск минимальной ошибки. Оптимизация — это непрерывный процесс работы над ошибками. Понимая, как работает под капотом градиентный спуск, мы получаем возможность лучше настраивать свои модели, быстрее находить идеальные гиперпараметры и увереннее ориентироваться в мире искусственного интеллекта.
Советуем дополнительно почитать по теме:
- Эмбеддинги в поиске: векторы, косинусное сходство и RAG — как поисковик превращает ваш запрос в числовой вектор и находит смысл, а не слова: обратный индекс, Word2Vec, BERT и RAG.
- Запускаем нейросеть на домашнем компьютере — пошаговое руководство для начинающих: как установить и запустить настоящую нейросеть у себя на компьютере.
- Ставим Invoke AI — сразу 12 нейросетей для работы с картинками с удобным веб-интерфейсом — как поставить локальный веб-интерфейс для работы с нейросетями и изображениями, если хочется перейти от теории к запуску моделей.
- Топ-ИИ для программистов в 2026: как нейросети пишут код за вас — GitHub Copilot, ChatGPT, Claude и другие инструменты для кода: где они помогают разработчику, а где всё ещё требуют проверки человеком.
- 20 AI GitHub-репозиториев для разработчика в 2026 году — подборка свежих репозиториев для локального запуска моделей, дообучения LLM, эмбеддингов в RAG, продакшен-инференса и работы с современными AI-инструментами.
Бонус для читателей
Если вам интересно погрузиться в мир ИИ и при этом немного сэкономить, держите наш промокод на курсы Практикума. Он даст вам скидку при оплате, поможет с льготной ипотекой и даст безлимит на маркетплейсах. Ладно, окей, это просто скидка, без остального, но хорошая.























